Turn raw data into decisions you can trust.
From ingestion to insight, we build fast, reliable big data pipelines, lakes and analytics with senior, AI-augmented data engineers who own delivery end to end.
- Batch & streaming
- Petabyte-ready
- Governed by design
Every layer of your data platform.
One senior team across the full data stack, ingestion to insight.
Data pipelines & ETL
Reliable batch and streaming pipelines that move, clean and transform data at scale.
Data lakes & lakehouses
Centralised, cost-efficient storage that unifies structured and unstructured data.
Warehousing & BI
Modelled warehouses and dashboards that turn raw events into business answers.
Real-time analytics
Streaming systems that surface metrics, alerts and trends as events happen.
Data governance & quality
Lineage, validation and access controls that keep data accurate and trusted.
AI & ML data layers
Feature stores and curated datasets that power LLM and machine-learning workloads.
How we build data platforms that scale.
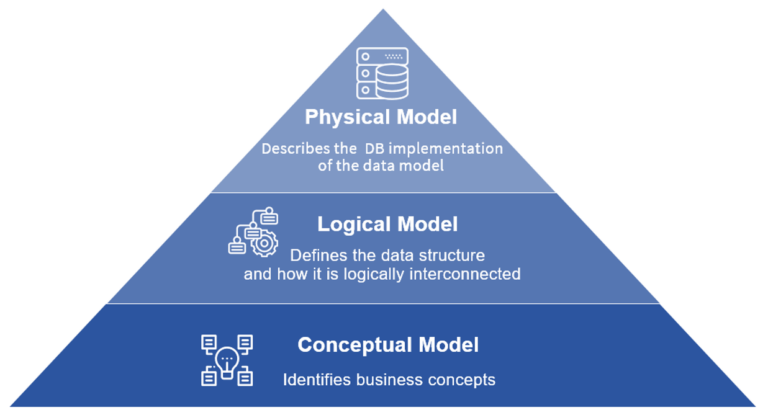
Model the data first
We map sources, volumes and access patterns up front, designing schemas and partitioning that stay fast and cheap as data grows from gigabytes to petabytes.
Quality & governance
Validation, lineage and tests run inside every pipeline, so downstream dashboards and models are built on data your business can actually trust.
Automate & scale
Orchestration, CI/CD and AI-assisted monitoring keep pipelines running reliably, catching failures and cost spikes before they reach your users.
A modern, proven data stack.
Big data questions, answered.
How long does it take to stand up a data pipeline?
A first production pipeline typically ships in 6–10 weeks; full platforms run in continuous sprints. We give you a milestone plan after a short discovery call.
Can you work with our existing data warehouse or lake?
Yes. We regularly extend existing Snowflake, BigQuery and Databricks setups, we start with an audit, then improve modelling, performance and data quality from there.
How do you handle data security and ownership?
All data, pipelines and IP are yours from day one. We work inside your cloud accounts with signed NDAs, role-based access and encryption in transit and at rest.
How do you keep pipelines reliable and costs under control?
Senior-only engineers, automated data tests, orchestration and AI-assisted monitoring catch failures and runaway cost early, with transparent sprint reporting throughout.
Sitting on data you can't use yet?
Tell us what you're collecting, we'll propose a data architecture and a senior team to make it useful.