Ship faster with safer, automated releases.
From CI/CD pipelines to infrastructure as code and 24/7 observability, we automate your delivery with senior, AI-augmented engineers who own reliability end to end.
- Automated pipelines
- Infrastructure as code
- Reliable by design
Every layer of your delivery pipeline.
One senior team across the full DevOps lifecycle, from commit to production.
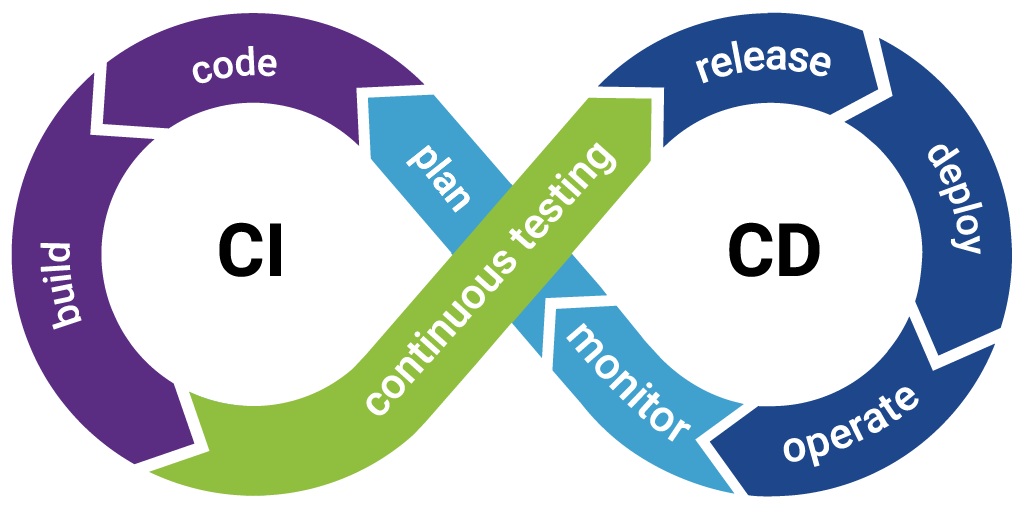
CI/CD pipelines
Automated build, test and deploy pipelines that release on every merge, safely and repeatably.
Infrastructure as code
Terraform and Pulumi to version, review and provision your whole cloud estate reproducibly.
Containers & Kubernetes
Dockerised workloads on managed Kubernetes with autoscaling, rollouts and self-healing.
Observability
Metrics, logs and traces with actionable alerting so you catch incidents before users do.
DevSecOps
Security scanning, secrets management and policy-as-code shifted left into the pipeline.
AI-assisted ops
LLM-powered runbooks, anomaly detection and automated triage to cut mean time to recovery.
How we make delivery fast and reliable.
Assess & baseline
We audit your pipelines, infrastructure and incident history, then baseline deployment frequency, lead time and failure rate so every change is measured against real numbers.
Automate everything
We codify infrastructure, build self-service CI/CD and replace manual steps with repeatable pipelines, so releases are one click, not a fragile checklist.

Observe & harden
End-to-end monitoring, alerting and AI-assisted incident triage keep systems healthy, while progressive rollouts and rollbacks make every deploy low-risk.
A modern, proven DevOps toolchain.
DevOps questions, answered.
How quickly can you set up a CI/CD pipeline?
A working pipeline for an existing app is usually live in 2–4 weeks; full platform automation runs in continuous sprints. We start with a short discovery and a baseline of your current delivery metrics.
Can you improve our existing infrastructure instead of rebuilding?
Yes. We routinely take over running environments, we begin with an audit, then incrementally codify infrastructure, harden pipelines and add observability without disrupting live traffic.
Do you provide on-call and incident support?
We can run on-call rotations and SRE coverage with daily global overlap, backed by runbooks, alerting and AI-assisted triage to keep mean time to recovery low.
Which cloud platforms do you work with?
We work across AWS, Google Cloud and Azure, plus Kubernetes anywhere. Infrastructure is defined as code so your setup stays portable and reproducible.
Want faster, safer releases?
Tell us about your stack, we'll propose a pipeline, infrastructure plan and a senior team to deliver it.