
Modern Data Platforms for AI-Driven Organizations: Building the Foundation for Enterprise Intelligence
A modern data platform for AI is the governed foundation that makes enterprise intelligence possible. Here is...
Modern BI architecture explained: from data warehouses to lakehouse and self-service analytics, with a reference architecture and governance.
Modern BI architecture is the layered design that moves data from operational systems through storage, modelling, and a governed semantic layer into the hands of business users, so that analytics is both trustworthy and self-service. The shape has changed in less than a decade: from rigid data warehouses feeding a handful of analysts, to data lakes, to the lakehouse, and now to semantic layers that let non-technical staff answer their own questions without breaking governance.
The pressure is real. Self-reported data-driven culture roughly doubled to about 48% in 2024, up from around 24% a few years earlier [6], yet most of those organisations still wrestle with conflicting numbers, slow reports, and dashboards nobody trusts. The architecture underneath is usually the cause.
This guide walks the full evolution: warehouse to lake to lakehouse to a governed semantic layer and true self-service. We cover a reference architecture, a decision framework, trade-off analysis, a real-world pattern, costs, a phased roadmap, the mistakes that quietly destroy trust, and a clear build-versus-buy recommendation for senior technology buyers in the UK, Australia, the US, and Singapore.
Key Takeaways
- Modern BI is a layered stack: ingestion, storage (warehouse, lake, or lakehouse), transformation, a governed semantic layer, and the consumption tools on top. The semantic layer is the piece most organisations skip and most need.
- The lakehouse pattern, championed by Databricks and Snowflake as they converge, removes the old warehouse-versus-lake split by putting warehouse-grade tables on open lake storage.
- Self-service without governance produces chaos: forty dashboards with five definitions of "active customer". A semantic layer with certified metrics is the fix, not a policy memo.
- Data-driven culture self-reported at about 48% in 2024, up from roughly 24% [6], but tooling alone does not deliver it. People, definitions, and ownership do.
- For most mid-market and enterprise teams, buy the platform (warehouse or lakehouse plus a BI tool) and build the models, pipelines, and semantic layer. Building storage from scratch is rarely justified.
Business intelligence used to mean one thing: a data warehouse, a nightly batch load, and a reporting tool that a small central team controlled. That model still works for stable financial reporting, but it cannot keep pace with the volume, variety, and speed of data that modern organisations generate. Modern BI architecture is the answer to that mismatch.
At its core, modern BI is a set of layers, each with one job. Get the layering right and you can swap tools, scale teams, and add governance without rebuilding. Get it wrong and you end up with a tangle of point-to-point extracts that nobody can audit.
The mistake most teams make is investing heavily in storage and consumption while ignoring transformation and the semantic layer. That is exactly why so many BI programmes produce dashboards that disagree with each other.
To choose the right storage layer, you need to understand why the field evolved through three distinct patterns. Each solved the previous one's weakness and introduced its own.
The classic data warehouse, built on structured, schema-on-write tables, was designed for clean, governed reporting. Tools like Teradata, then Amazon Redshift, Google BigQuery, and Snowflake, made it fast to query well-modelled data. The strength is governance and query performance on structured data. The weakness is cost and rigidity: warehouses struggle with semi-structured data, machine-learning workloads, and the sheer volume of raw event data, and storage is expensive.
Data lakes flipped the model. Dump everything (structured, semi-structured, unstructured) into cheap object storage like Amazon S3 or Azure Data Lake Storage, then apply schema on read. The strength is cost and flexibility: store petabytes cheaply and feed data science. The weakness is governance. Without transactions, schema enforcement, or reliable metadata, lakes degrade into "data swamps" where nobody trusts the contents and queries are slow.
The lakehouse merges the two. It puts warehouse-grade features (ACID transactions, schema enforcement, time travel, fast SQL) directly on top of open table formats over cheap lake storage. Open formats like Delta Lake, Apache Iceberg, and Apache Hudi are the enabling technology. Databricks and Snowflake have converged on this pattern from opposite starting points, which is the clearest signal that the lakehouse is now the mainstream direction rather than a fad.
| Dimension | Data warehouse | Data lake | Lakehouse |
|---|---|---|---|
| Primary data type | Structured | All types, raw | All types, governed |
| Schema | Schema-on-write | Schema-on-read | Schema enforced on open tables |
| Storage cost | Higher | Lowest | Low (object storage) |
| Transactions (ACID) | Yes | No | Yes (Delta/Iceberg/Hudi) |
| BI query performance | Excellent | Poor without tuning | Good to excellent |
| ML / data science fit | Limited | Strong | Strong |
| Governance maturity | High | Low by default | High with catalog |
| Best for | Stable financial reporting | Raw data and exploration | Unified BI plus ML |
The practical takeaway: a greenfield analytics platform in 2026 should default to a lakehouse or a cloud warehouse with open table support, not a pure lake and not a closed legacy warehouse. The decision then turns on your existing investments and skills, which we frame below.
Self-service analytics is the goal that justifies the whole architecture: business users answering their own questions without filing a ticket. But self-service without a semantic layer is how organisations end up with forty dashboards and five different definitions of "active customer". The semantic layer is the single most underrated component of modern BI.
A semantic layer sits between your modelled tables and your consumption tools. It defines metrics, dimensions, and relationships once, in a governed and version-controlled place, so that "monthly recurring revenue" means the same thing in a Power BI dashboard, a Looker explore, and an AI assistant's answer. It decouples business logic from any single tool.
There are three common approaches. Tool-native models (Power BI's semantic model, Looker's LookML) live inside one BI platform. Headless or universal semantic layers (dbt Semantic Layer, Cube, AtScale) sit outside any tool and serve many. Warehouse-native metric definitions push logic into the warehouse itself. The headless approach is gaining ground because it prevents lock-in and serves embedded apps, notebooks, and AI agents alike.
Governance has a reputation for slowing teams down. Done well, it does the opposite. Certified datasets, clear ownership, documented metrics, and access controls are what let you safely open self-service to hundreds of people. The principle is "freedom within a framework": users explore freely on top of trusted, certified building blocks they cannot accidentally redefine.
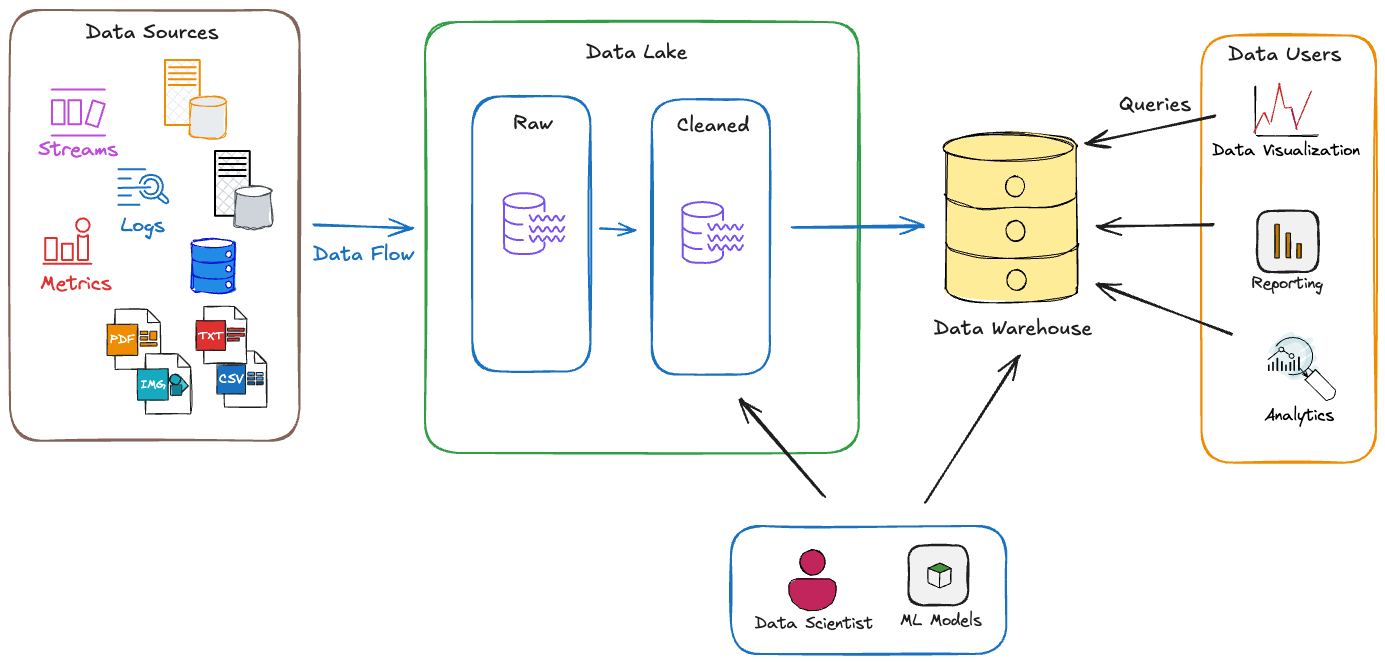
Here is a vendor-neutral reference architecture that holds up across cloud providers and BI tools. It is the layered model described above, drawn end to end. The medallion pattern (bronze, silver, gold) is shown because it is the most widely adopted way to organise transformation inside a lakehouse.
SOURCES INGESTION STORAGE (LAKEHOUSE) SEMANTIC CONSUMPTION
+-----------+ +-----------+ +-------------------+ +-----------+ +---------------+
| ERP / CRM | ---> | ELT / | ---> | Bronze (raw) | | | | Dashboards |
| Product DB| ---> | CDC | | | | | Certified | | Self-service |
| SaaS APIs | ---> | (Fivetran,| ---> | Silver (cleaned) | ---> | metrics & | --> | Embedded BI |
| Events | ---> | Airbyte, | | | | | dimensions| | Notebooks |
| Files | | Kafka) | | Gold (modelled) | | (dbt SL, | | NL / AI query |
+-----------+ +-----------+ +-------------------+ | LookML) | +---------------+
| +-----------+
Transformation (dbt / SQL) |
| |
+-----------------------------------------------+
| GOVERNANCE: catalog, lineage, access, quality |
+-----------------------------------------------+
Two things in this diagram matter most. First, governance is a horizontal concern that touches every layer, not a bolt-on. Second, the semantic layer is the single doorway between modelled data and every consumption tool, which is what keeps definitions consistent across dashboards, notebooks, and AI agents. Teams that build this foundation properly find that adding AI-driven analytics later is far simpler, a point reinforced in our companion guide on modern data platforms for AI-driven organisations.
There is no universally correct architecture, only the right fit for your data volume, team maturity, and use cases. Use the questions below to land on a starting pattern, then refine.
| Your situation | Recommended pattern | Why |
|---|---|---|
| Lean team, structured data, fast reporting | Cloud warehouse + ELT + tool-native semantic model | Lowest operational burden, quick time to value |
| Mixed data, BI plus ML, growing scale | Lakehouse (Databricks or Snowflake) + dbt + headless semantic layer | One platform for analytics and data science, no data duplication |
| Many domains, large org, distributed ownership | Lakehouse + data-mesh domains + governed catalog | Scales ownership and governance across teams |
| Heavy embedding into customer-facing apps | Warehouse or lakehouse + headless semantic layer + embedded BI | Consistent metrics across product and internal use |
| Legacy on-premise warehouse, regulated | Phased migration to cloud warehouse, keep governance strict | Reduce risk, modernise incrementally |
Every choice trades one virtue for another. The lakehouse buys flexibility and unified ML at the cost of more engineering complexity than a managed warehouse. A headless semantic layer buys tool independence at the cost of an extra system to run and learn. Pushing self-service wide buys speed and engagement at the cost of governance overhead you must fund up front.
The trap is optimising a single dimension. Teams that chase the cheapest storage end up with a swamp. Teams that chase maximum governance end up with a central bottleneck that the business routes around with spreadsheets. The art is balancing flexibility, cost, performance, and trust for your actual workload, not the architecture on a conference slide.
The clearest real-world signal in modern BI is not one company's story but the convergence of the two market leaders. Databricks began as a data-lake and machine-learning platform built on Apache Spark, then added Delta Lake, a SQL warehouse layer, and the Unity Catalog for governance, moving toward the warehouse. Snowflake began as a cloud data warehouse, then added support for unstructured data, Apache Iceberg tables, Snowpark for data engineering and machine learning, and external table access, moving toward the lake.
Both companies now describe themselves as unified data platforms, and both center on open table formats. That convergence is the strongest evidence that the lakehouse is the destination, because two fierce competitors arrived at the same architecture from opposite directions. For a buyer, the practical lesson is to design around open table formats (Delta or Iceberg) rather than betting your entire data estate on one vendor's proprietary internals.
A typical enterprise pattern that follows from this: land raw data in object storage as Iceberg or Delta tables, transform with dbt into a medallion structure, govern with a catalog like Unity Catalog or an open alternative, expose certified metrics through a semantic layer, and let teams consume through Power BI, Tableau, Looker, or notebooks. The same governed gold tables feed both the finance dashboard and the churn-prediction model. Choosing between the consumption tools themselves is a decision worth its own analysis, which we cover in our comparison of the leading platforms in Power BI vs Looker vs Tableau in 2026.
Modern BI is not a big-bang project. The organisations that succeed treat it as a sequence of phases, each delivering value and earning trust before the next begins. A practical sequence looks like this.
This phasing mirrors the broader culture change that BI maturity requires. The technology is only half the work, a theme we develop fully in our practical BI transformation roadmap for building a data-driven organisation. Teams that lack in-house data engineering depth often accelerate phases 1 and 2 with a partner: groups like Mind Supernova help enterprises stand up the lakehouse, transformation, and semantic layers, then hand operations back to internal teams.
Most BI failures are not technical. They are failures of definition, ownership, and sequencing. These are the patterns we see most often.
BI cost is broader than software licences. The biggest surprises come from compute and people, not the line items buyers anticipate. The categories below frame total cost of ownership. Figures are industry estimates and vary widely by scale and region; treat them as planning ranges, not quotes.
| Cost category | What drives it | How to control it |
|---|---|---|
| Storage | Volume of raw and modelled data; retention | Object storage, tiering, lifecycle policies, partition pruning |
| Compute / query | Query volume, concurrency, inefficient SQL, auto-suspend settings | Right-size warehouses, cache, materialise gold tables, FinOps monitoring |
| BI tool licensing | Per-user vs capacity pricing; viewer vs creator seats | Match licence model to user mix; avoid over-licensing viewers |
| Pipeline / ELT tools | Connector count, row volume (consumption pricing) | CDC over full reloads; consolidate redundant pipelines |
| People | Data engineers, analytics engineers, platform owners | Often the largest line item; augment selectively rather than over-hiring |
The single most common cost shock is compute. Consumption-priced warehouses make a badly written query or a dashboard that refreshes too often expensive in ways an annual licence never was. This is why FinOps discipline (visibility, accountability, and optimisation of cloud spend) belongs in the roadmap from phase one, not after the first surprise invoice.
The build-versus-buy question in modern BI is not all-or-nothing. The right answer is to buy the commodity layers and build the parts that encode your business.
Storage, query engines, and BI tools are mature, commoditised, and operated far more cheaply by cloud vendors than you can manage yourself. Building a data warehouse engine or a visualisation tool from scratch in 2026 is almost never justified. Buy a managed cloud warehouse or lakehouse (Snowflake, Databricks, BigQuery) and a leading BI tool. The exception is genuinely extreme scale or unusual regulatory isolation, and even then the bar is high.
Your transformation logic, data models, and certified metric definitions are where your competitive understanding of the business lives. These should be built and owned in-house, version-controlled, and treated as a product. Outsourcing your metric definitions outsources your understanding of your own business.
| Layer | Recommendation | Rationale |
|---|---|---|
| Storage / query engine | Buy (managed) | Commoditised; vendors operate it cheaper and better |
| Ingestion / ELT | Buy connectors, build CDC where critical | Connectors are cheap; bespoke only for unique sources |
| Transformation / models | Build, own in-house | Encodes business logic; must be controlled |
| Semantic layer | Build on bought tooling | Definitions are yours; tooling is not |
| BI / consumption tool | Buy | Mature market; no advantage in building |
For the build portions, capacity is the constraint for most teams. Standing up a lakehouse, dbt transformation layer, and semantic layer well takes scarce data-engineering skill. This is a natural place to bring in dedicated help. Mind Supernova, a Vietnam-based software and data engineering partner founded in 2023, works as an offshore extension with 4+ hours of daily UK overlap, with senior engineers who can start in 5 to 7 days, drawing on our team's collective experience across data platforms. Schedule a call if you want to discuss your BI architecture before committing to a pattern. You can also explore how we structure dedicated data engineering teams or augment an existing team.
A data warehouse stores structured, schema-on-write data optimised for fast SQL reporting but struggles with raw, semi-structured, or machine-learning workloads. A lakehouse puts warehouse features (ACID transactions, schema enforcement, fast SQL) on top of cheap open-format lake storage, so it handles both BI and data science in one place without copying data.
Yes, if you want self-service to scale. Without a semantic layer, every user defines metrics their own way, producing conflicting dashboards and lost trust. A semantic layer defines metrics like revenue or active customers once, in a governed place, so every tool and AI assistant returns the same number. It is the foundation of trustworthy self-service.
Both have converged on the lakehouse pattern and serve it well. Snowflake suits teams prioritising SQL simplicity and a managed warehouse heritage; Databricks suits teams with heavy data-science and Spark workloads. Design around open table formats (Delta or Iceberg) so the decision is less binding, then choose on team skills and existing investment.
A focused team can deliver a trusted first use case in 8 to 12 weeks on a managed platform. A governed semantic layer and self-service rollout typically take 6 to 12 months. Full maturity, including domain ownership and FinOps, is ongoing. Phasing matters more than speed: deliver value early and expand on proven trust.
Skipping governance and the semantic layer while rushing to dashboards. Teams that jump straight to visualisation end up with conflicting numbers within a year, and once trust is lost it is expensive to rebuild. Define certified metrics, assign owners, and document definitions before opening self-service widely.
Modern BI architecture has settled into a clear shape: a lakehouse or cloud warehouse for storage, version-controlled transformation, a governed semantic layer, and self-service consumption on top, with governance running through every layer. The technology is no longer the hard part. The discipline of definitions, ownership, and phasing is.
This quarter: pick your storage pattern with the decision framework, stand up version-controlled transformation, and deliver one trusted end-to-end use case. Next 90 days: introduce a data catalog and your first certified metrics in a semantic layer before you open self-service to anyone. Resist the urge to boil the ocean.
If you want a second opinion on your architecture or extra engineering capacity to build the foundation, talk to our engineering team. The right help early prevents the swamp later. For the wider organisational change that BI maturity depends on, read our companion piece on big data architecture in 2026: Lambda, Kappa, and lakehouse compared.
A modern data platform for AI is the governed foundation that makes enterprise intelligence possible. Here is...

Power BI vs Looker vs Tableau in 2026: a deep comparison of cost, modeling, governance, and embedding, with be...

Big data architecture in 2026: Lambda vs Kappa vs lakehouse compared, with streaming trade-offs and a clear de...