
How to Build a Data-Driven Organization: A Practical BI Transformation Roadmap
How to build a data-driven organization: a practical BI transformation roadmap across people, process, technol...
A modern data platform for AI is the governed foundation that makes enterprise intelligence possible. Here is the reference architecture, build-vs-buy, and roadmap.
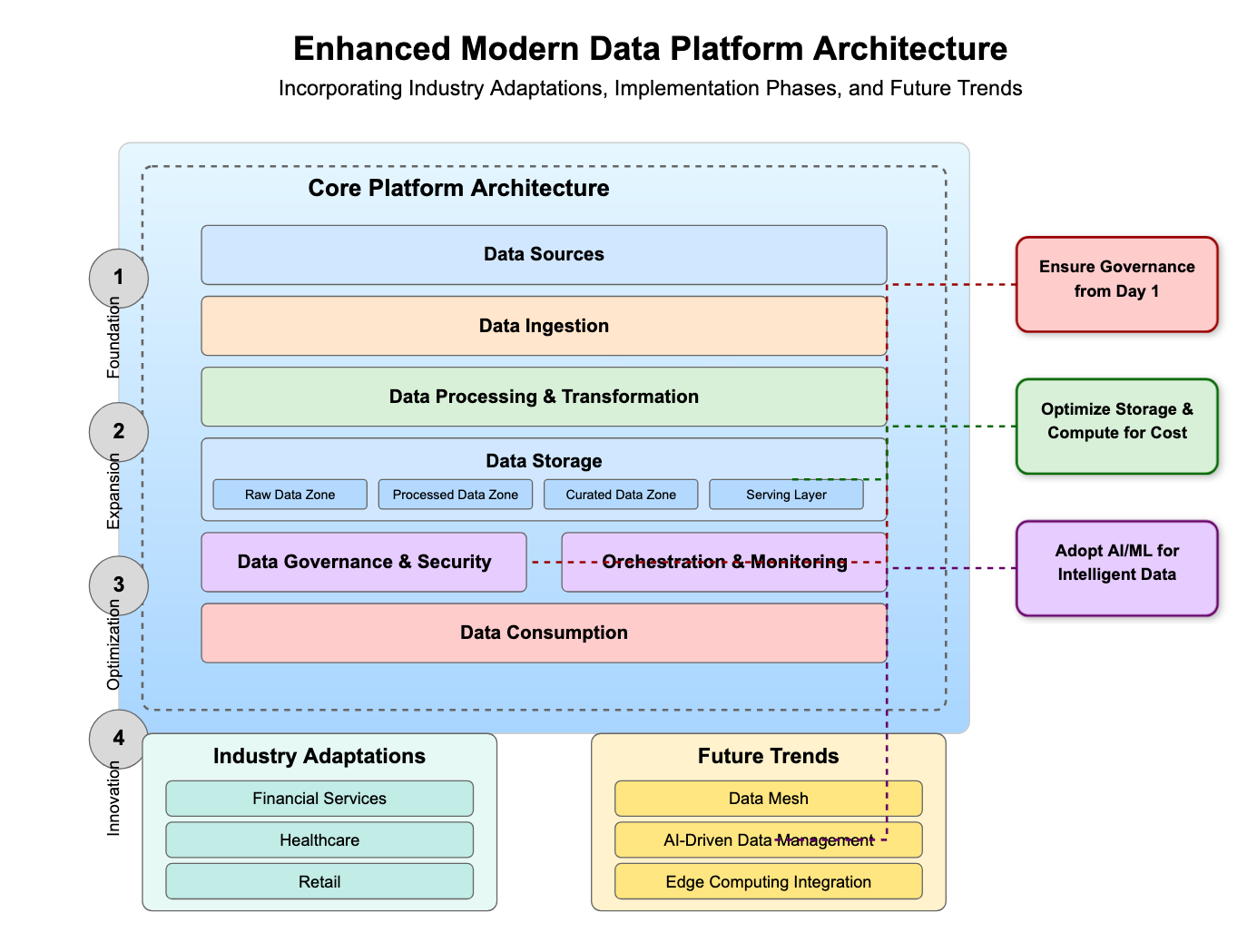
A modern data platform for AI is a unified, governed, and observable system for ingesting, storing, transforming, governing, and serving data so that analytics, machine learning, and generative AI workloads can all run on the same trustworthy foundation. It is not a single product. It is a layered architecture—ingestion and streaming, a lakehouse organized into quality tiers, a transformation and semantic layer, governance and catalog, feature stores for machine learning, vector stores for retrieval, and a serving layer—assembled so that data reaches a model clean, current, access-controlled, and explainable.
The reason this matters has become the defining lesson of enterprise AI: the bottleneck is almost never the model. Frontier models are commoditized and improving monthly, available through an API call. What separates the enterprises getting real returns from the ones stuck in perpetual pilots is the state of their data—whether it is consolidated or fragmented, governed or ungoverned, fresh or stale, and trusted or suspect. MIT Sloan research in 2025 found that data trust is the single largest barrier to scaling AI, cited by roughly three-quarters of data leaders. You can rent intelligence; you cannot rent your own data foundation.
This guide is written for Heads of Data, Chief Data Officers, and CTOs who own that foundation. It is vendor-neutral and practitioner-grade. It covers why data—not models—is the constraint, the modern reference architecture layer by layer, the build-versus-buy decision for each component, data quality and observability, governance and security, an implementation roadmap, the ROI math, and the pitfalls—data swamps and tool sprawl—that derail platforms before they deliver. For how this platform fits the broader technology stack, see our companion guide to the enterprise AI stack for 2026.
Key Takeaways
Data is the real bottleneck because models have become a commodity while data foundations have not. Any enterprise can call a state-of-the-art large language model through an API, and the gap between the best and second-best model narrows with every release. What no vendor can supply is your proprietary, governed, well-modeled data—and that is exactly where most organizations are weakest.
The pattern shows up in every credible survey. McKinsey's state-of-AI research has repeatedly found that the organizations capturing value from AI are distinguished less by their model choices than by their data and operating-model maturity. MIT Sloan's 2025 work put a number on it: data trust is the top barrier to scaling AI for the majority of data leaders. When pilots stall, the post-mortem rarely blames the model—it blames data that was fragmented across silos, missing lineage, inconsistent definitions, stale pipelines, or access controls that legal would never approve for production.
This has a direct consequence for how you spend. Pouring budget into model experimentation while the data foundation stays broken is the most common and most expensive mistake in enterprise AI. A retrieval-augmented chatbot grounded in a poorly governed knowledge base will confidently cite the wrong policy. A fraud model trained on features that drift silently will degrade in weeks. An agent that reads from systems with no access controls becomes a security incident waiting to happen. In every case, the model worked; the data foundation did not.
The implication for leaders is liberating once accepted: you do not need to win the model race. You need to win the data race—and that is a race you can actually control. The rest of this guide is about how.
A modern data platform reference architecture is a set of layers, each with a clear responsibility, that together move data from raw source to AI-ready product. The specific vendors vary, but the shape is remarkably consistent across mature enterprises. The table below is the blueprint the rest of this article expands on.
| Layer | What it does | Why AI needs it | Representative technologies |
|---|---|---|---|
| 1. Ingestion & streaming | Captures data from sources in batch and real time; change data capture from operational systems | AI needs fresh data; streaming powers real-time features and up-to-date retrieval | Kafka, Kinesis, Debezium, Fivetran, Airbyte |
| 2. Lakehouse storage (medallion) | Unifies a data lake and warehouse; organizes data into bronze (raw), silver (cleaned), gold (business-ready) tiers | One governed store for both analytics and AI; ACID reliability on open formats | Delta Lake, Apache Iceberg, Apache Hudi on object storage |
| 3. Transformation | Cleans, conforms, joins, and models data into trusted tables | Reproducible, tested pipelines produce the trusted data AI depends on | dbt, Spark, SQL engines, orchestration (Airflow, Dagster) |
| 4. Governance, catalog & lineage | Discovers, documents, classifies, and tracks the origin of every dataset | Trust, access control, explainability, and regulatory auditability | Catalog and lineage platforms, Unity Catalog, OpenLineage |
| 5. Semantic layer | Defines metrics, entities, and business meaning once, consistently | Gives both BI and AI a single, unambiguous definition of "revenue" or "customer" | Metric/semantic layers, headless BI |
| 6. Feature store | Computes, stores, and serves consistent features for ML, online and offline | Eliminates training-serving skew; reuses features across models | Feast, Tecton, managed feature stores |
| 7. Vector store | Stores embeddings and powers semantic/hybrid retrieval | The retrieval backbone of RAG and grounded generative AI | Weaviate, Milvus, pgvector, managed vector search |
| 8. Serving & consumption | Exposes data, features, and context to models, apps, and analysts | Low-latency, governed access for inference, agents, and dashboards | Online stores, APIs, model/inference endpoints |
Two principles hold the architecture together. First, openness: open table formats and open standards prevent lock-in and let analytics and AI share one copy of the data instead of duplicating it. Second, governance as a cross-cutting layer, not a bolt-on: catalog, lineage, access control, and observability apply across every layer rather than sitting at the end.
The ingestion layer captures data from operational databases, SaaS applications, event streams, files, and APIs—in both scheduled batches and continuous streams. For AI, freshness is a feature, not a nicety: real-time fraud detection, dynamic personalization, and up-to-date retrieval all depend on data that arrives in seconds, not nightly. Change data capture (CDC) tools stream row-level changes out of transactional systems without hammering them, while streaming platforms like Kafka or Kinesis carry high-volume events. The design goal is a single, reliable path from every source into the lakehouse, with schema handling and error capture built in so bad data is quarantined rather than silently propagated.
The lakehouse architecture is the heart of the modern platform: it combines the low-cost, flexible storage of a data lake with the reliability, performance, and ACID transactions of a data warehouse, using open table formats such as Delta Lake, Apache Iceberg, or Apache Hudi over cheap object storage. This matters for AI because it ends the long-standing split where analysts worked in a governed warehouse and data scientists worked in an ungoverned lake. With a lakehouse, both run on one governed copy.
Within the lakehouse, the medallion architecture—popularized by Databricks and now a de facto industry pattern—organizes data into three progressively refined tiers:
The medallion pattern is not bureaucracy. It is what gives you reproducibility and trust: when a model behaves oddly, you can trace its inputs from gold back through silver to the raw bronze record, which is exactly the lineage regulators and auditors increasingly demand. Treat the tiers as logical contracts about data quality, not as a rigid mandate to physically copy data three times for every dataset.
The transformation layer turns raw data into trusted data through tested, version-controlled pipelines. Modern practice borrows from software engineering: transformations live in source control, run through CI, carry automated tests and data-quality assertions, and are orchestrated as dependency graphs. This is what makes "silver" data trustworthy rather than merely cleaned-looking.
Above it sits the semantic layer, an often-overlooked component that becomes essential in the AI era. The semantic layer defines business concepts—metrics like "net revenue," entities like "active customer"—once, in one place, so every consumer gets the same answer. For traditional BI this prevents the familiar problem of five dashboards reporting five different revenue numbers. For AI it is even more important: when an LLM or an agent queries your data, the semantic layer is what stops it from inventing its own (wrong) definition of a core business term. A well-defined semantic layer is increasingly the difference between an AI assistant that gives trustworthy answers and one that hallucinates plausible nonsense over real tables.
A feature store is a specialized system that computes, stores, and serves the features—the engineered input variables—that machine learning models consume. Its core job is to eliminate training-serving skew: the dangerous, common bug where a model is trained on features calculated one way in batch but served features calculated a slightly different way in production, quietly degrading accuracy. A feature store provides one definition of each feature, an offline store for training and an online store for low-latency inference, and reuse across teams so the same "customer 30-day transaction count" is not re-engineered five times.
For enterprises doing serious predictive ML—fraud scoring, churn prediction, recommendation, forecasting—a feature store is foundational. It enforces consistency, accelerates new model development through reuse, and gives governance a place to manage feature-level access and lineage. Not every organization needs one on day one, but any organization running more than a handful of production ML models will eventually feel the pain a feature store removes.
A vector database stores embeddings—numerical representations of text, images, or other content—and retrieves the most semantically relevant items for a given query. It is the retrieval backbone of retrieval-augmented generation (RAG), the architecture that grounds large language models in your proprietary knowledge so they answer from your documents rather than from their training data alone. When an AI assistant answers a question about your internal policy correctly, a vector store almost certainly fetched the relevant policy text first.
It is worth being precise about the distinction practitioners now draw: a lightweight vector store handles embedding storage and similarity search, while a full vector database adds production-grade persistence, indexing, metadata filtering, and horizontal scale. For enterprise RAG, the consensus in 2025 is that pure vector similarity is not enough—production systems combine dense vector search with sparse keyword (BM25) search and a reranking step, because vector search alone misses exact matches and keyword search alone misses meaning. Options range from PostgreSQL with the pgvector extension (pragmatic when you already run Postgres) to dedicated engines like Weaviate or Milvus built to scale to billions of vectors. For the full picture of grounding AI in enterprise knowledge, see our guide to enterprise RAG systems.
Feature stores and vector databases solve fundamentally different problems and a mature AI platform usually needs both. A feature store serves structured features to predictive ML models and exists to guarantee consistency between training and serving. A vector database serves semantic context to generative models and exists to retrieve relevant unstructured knowledge. One feeds the model that scores a transaction; the other feeds the model that answers a question. Confusing them—trying to do RAG out of a feature store, or serving ML features from a vector index—is a common architectural mis-step that an explicit reference architecture prevents.
The build-versus-buy decision should be made component by component, governed by one rule: own what is differentiating, buy what is commodity. No enterprise should hand-build object storage or a vector index in 2026, and almost none should outsource the modeling of their own proprietary data. The art is in the middle layers.
| Component | Default recommendation | Rationale |
|---|---|---|
| Object storage & compute | Buy (cloud) | Pure commodity; no advantage in operating your own |
| Lakehouse table format | Buy / adopt open standard | Use open formats (Delta, Iceberg) to avoid lock-in |
| Ingestion connectors | Buy for standard sources; build for niche | Connector maintenance is undifferentiated toil |
| Transformation logic | Build (on bought tools) | Your business logic is differentiating; the engine is not |
| Semantic / metric layer | Build (on a framework) | Your metric definitions are uniquely yours |
| Governance & catalog | Buy platform; configure to your policy | Mature tools exist; rebuilding wastes years |
| Feature store | Buy or open-source | Well-solved; managed and OSS options are strong |
| Vector database | Buy / open-source | Fast-moving, well-served market; do not hand-roll |
| Orchestration & observability | Buy / open-source | Reliability tooling is commodity infrastructure |
The deeper question behind build-versus-buy is rarely about a single tool; it is about whether you have the engineering capacity to assemble and operate the platform on the timeline the business expects. The components are mostly available—the scarce resource is the senior data and platform engineering talent to integrate them into a coherent, governed, observable whole and keep it running. This is precisely the gap that a specialist Data & AI Transformation partner like Mind Supernova is built to close: standing up the lakehouse, the governance and lineage layer, the feature and vector infrastructure, and the pipelines—to your standards and your cloud—while transferring capability to your team rather than creating a dependency.
Data is AI-ready when it is trustworthy, fresh, well-described, access-controlled, and traceable—and you can prove all of that continuously, not just at a point in time. AI raises the stakes on data quality because models amplify whatever they are fed: a subtle error in a feature or a stale field in a knowledge base does not stay contained, it propagates into every decision and answer the model produces.
Two capabilities make data AI-ready in practice:
Observability and quality together are what convert a data lake into a data foundation you can put behind a customer-facing AI system. Without them, you do not actually know whether your data is trustworthy—you are hoping it is, which is not a posture any CDO wants to defend to the board after an incident.
You govern a data platform for AI by making catalog, lineage, access control, and policy enforcement cross-cutting layers that apply to every dataset—because in the AI era, governance is what makes data both trustworthy and legally defensible. Governance is not the enemy of speed here; done well, it is what lets risk, legal, and security say yes to production faster.
The governance foundation has several reinforcing parts:
Security must be designed in, not retrofitted: encryption in transit and at rest, secrets management, audit logging of every access, and data masking or tokenization for sensitive fields. The regulatory backdrop makes this urgent rather than optional. The EU AI Act imposes documentation, data-governance, and traceability obligations on high-risk AI systems, with major requirements phasing in through 2026—and you cannot meet them without the lineage and governance layers above. Anchoring your program to the NIST AI Risk Management Framework and ISO/IEC 42001 gives you a defensible, auditable structure. Governance is also the operating-model glue that an AI Center of Excellence uses to set standards once and reuse them across every business unit.
The implementation roadmap for a modern data platform proceeds in phases that each deliver usable capability, rather than a multi-year program that delivers nothing until the end. The cardinal rule is to build the platform just ahead of demand—enough foundation to support the next wave of use cases, built to a standard the wave after that can reuse.
| Phase | Focus | Key deliverables | Typical duration |
|---|---|---|---|
| 1. Foundation | Land and govern data | Lakehouse with bronze/silver tiers, core ingestion, catalog, baseline access control | 2–4 months |
| 2. Trust | Make data reliable | Tested transformations, gold tables, data-quality checks, observability, lineage | 2–4 months |
| 3. AI enablement | Serve AI workloads | Semantic layer, feature store, vector store, serving APIs for first use cases | 3–6 months |
| 4. Scale & self-serve | Industrialize | Reusable platform services, FinOps, self-serve enablement, continuous governance | Ongoing |
A few sequencing principles separate roadmaps that succeed from those that stall. Start with a high-value, well-bounded use case to anchor the foundation—never build the platform in the abstract "because we'll need it." Tie each phase to a use case that proves it. Make governance and observability part of phase one, not a later cleanup. And resist the temptation to adopt every layer at once: many enterprises legitimately defer a feature store or a heavyweight semantic layer until the use cases demand them. The roadmap for the data platform should slot directly into the broader enterprise AI transformation roadmap, where the data foundation is explicitly the first phase that makes everything after it possible.
The ROI of a modern data platform comes from three compounding sources: the AI use cases it unlocks, the engineering time it saves, and the risk and cost it removes. Because the platform is a shared foundation, its return is leverage—every use case built on it is cheaper, faster, and more reliable than it would have been on a fragmented stack.
The value shows up in concrete ways:
To make the ROI case credible, measure it honestly. Model the total cost of ownership—storage, compute, tooling licenses, inference, and the engineering to run it—and apply FinOps discipline so cloud and token costs do not quietly erase the gains. Tie the platform investment to the specific use cases it unblocks, and report value as the portfolio of outcomes those use cases produce, not as an abstract infrastructure line item the board cannot evaluate.
The two defining failure modes of data platforms are the data swamp and tool sprawl—and both are governance failures wearing technology costumes. Recognizing them early is the difference between a platform that compounds and one that quietly collapses under its own weight.
For Heads of Data, CDOs, and CTOs ready to act, the decisions that matter most:
A modern data platform for AI is a unified, governed system that ingests, stores, transforms, governs, and serves data so that analytics, machine learning, and generative AI can all run on the same trustworthy foundation. It is a layered architecture—ingestion and streaming, a lakehouse with medallion tiers, transformation and a semantic layer, governance and catalog, feature stores, vector stores, and serving—rather than a single product.
A data warehouse stores structured, modeled data optimized for analytics but struggles with the unstructured data and scale that AI needs. A data lakehouse combines the low-cost, flexible storage of a data lake with the reliability and ACID transactions of a warehouse, using open table formats. The lakehouse lets analytics and AI run on one governed copy of the data instead of maintaining separate, divergent systems.
The medallion architecture is a lakehouse design pattern that organizes data into three progressive quality tiers: bronze (raw data as it arrived), silver (cleaned, conformed, deduplicated data), and gold (business-ready, aggregated data for analytics and AI). It provides reproducibility, trust, and end-to-end lineage, which is why it has become a de facto standard for AI-ready data platforms.
A feature store computes, stores, and serves consistent structured features for machine learning models, eliminating training-serving skew. A vector database stores embeddings and retrieves semantically relevant content to power retrieval-augmented generation for generative AI. They solve different problems—predictive ML versus grounded generation—and a mature AI data platform typically needs both.
It is phased rather than a single delivery. A usable foundation—lakehouse, core ingestion, catalog, and baseline governance—commonly takes two to four months, with a trust phase and an AI-enablement phase adding several months each before the platform supports production AI broadly. Timelines depend most on existing data maturity and on whether the platform is built just ahead of real use cases rather than in the abstract.
Decide component by component. Buy or adopt open standards for commodity layers—object storage, lakehouse table formats, governance tooling, feature stores, and vector databases. Build the parts that are differentiating—your transformation logic and your semantic and metric definitions. The scarce resource is usually the senior engineering talent to integrate and operate the stack, which is where many enterprises bring in a specialist data platform partner.
Data is AI-ready when it is trustworthy, fresh, well-described, access-controlled, and traceable—and you can prove it continuously through automated data-quality checks and data observability. Because AI models amplify whatever they are fed, AI-ready data also requires lineage for explainability and a semantic layer so models inherit consistent business definitions rather than inventing their own.
The enterprises winning with AI are not the ones with the cleverest models—models are a commodity any competitor can rent. They are the ones with a data foundation worth building on: consolidated in a governed lakehouse, refined through medallion tiers, defined once in a semantic layer, served consistently through feature and vector stores, and trusted because quality, lineage, and observability are designed in rather than hoped for. That foundation is the durable advantage, because it is the one thing a competitor cannot buy off the shelf.
None of it requires a perfect, finished platform before you start. It requires a coherent reference architecture, governance from day one, and the discipline to build just ahead of real use cases while avoiding the swamp and the sprawl. If your AI ambitions are outrunning your data foundation—and for most enterprises they are—the highest-leverage next step is an honest assessment of which layer is your binding constraint and a roadmap to close it. When senior data and platform engineering capacity is the limiting factor, a Data & AI Transformation partner like Mind Supernova can help stand up the lakehouse, governance, and AI-serving layers to your standards while leaving a stronger in-house team behind. The architecture is well understood. The advantage goes to the organizations disciplined enough to build the foundation before they chase the use cases.
How to build a data-driven organization: a practical BI transformation roadmap across people, process, technol...

Modern BI architecture explained: from data warehouses to lakehouse and self-service analytics, with a referen...

Power BI vs Looker vs Tableau in 2026: a deep comparison of cost, modeling, governance, and embedding, with be...