
AI-Powered Software Development: Beyond Coding Assistants
Coding assistants are only the first step. Learn how AI-powered software development now spans the entire SDLC...
Legacy system modernization compared: strangler fig vs big bang vs incremental migration, with risk and cost trade-offs and a decision framework.
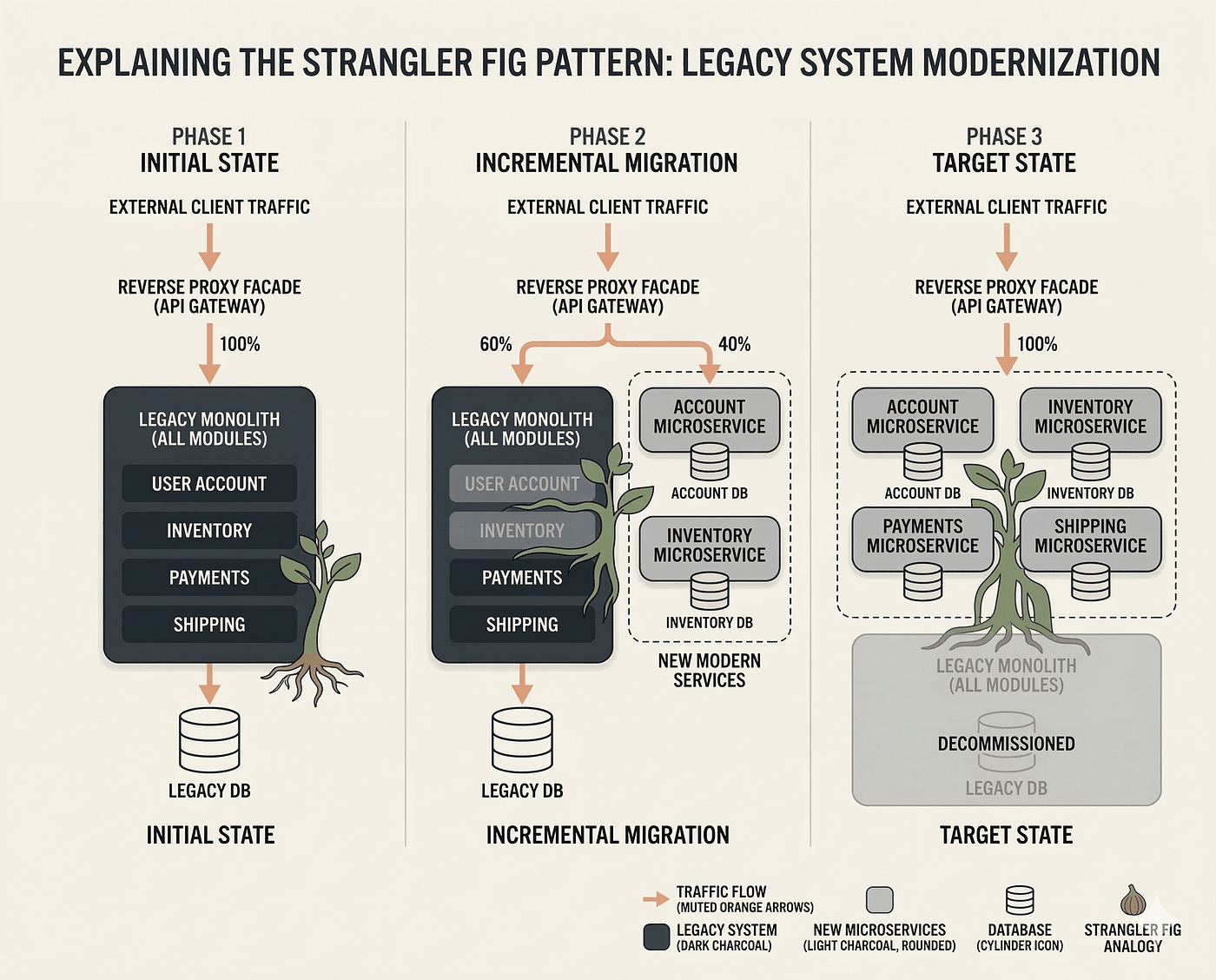
Legacy system modernization is the disciplined process of replacing or re-engineering ageing software without breaking the business that depends on it, and the right approach is almost always incremental rather than a single dramatic cutover. The three patterns you will hear named are strangler fig, big bang, and incremental migration. For most enterprises, the strangler fig pattern is the safest default, big bang is a last resort, and a phased incremental plan is the engine that delivers either one.
That sounds tidy. In practice, the decision is rarely obvious. A 14-year-old monolith with no tests, a retiring vendor platform, and a board demanding cloud savings all push you in different directions. The wrong call can stall delivery for two years, blow a budget, and erode the trust you need to keep funding the work.
This guide gives you a decision framework rather than a fashion. We compare strangler fig, big bang, and incremental migration on risk, cost, and time. We walk a real-world example, lay out a phased roadmap, list the mistakes that quietly sink these programmes, and close with a clear build-versus-buy recommendation for senior technology buyers.
Key Takeaways
- The strangler fig pattern, named by Martin Fowler, lets you grow a new system around the old one and retire legacy piece by piece, keeping both running until the last function is migrated [3].
- Big bang rewrites carry the highest risk: a single cutover with no fallback, a multi-year window with no value delivered, and a moving target as the legacy system keeps changing underneath you.
- Choose by coupling, risk tolerance, and seam quality. Tightly coupled systems with clear module boundaries suit incremental extraction; small, well-understood systems can sometimes justify a controlled big bang.
- Legacy maintenance consumes a large share of most IT budgets (industry estimate), so the business case is usually about freeing future capacity, not just cutting current cost.
- Modernization is a programme, not a project. Treat it in 90-day increments with measurable value at the end of each, or funding will evaporate before you finish.
"Legacy" is not an age. A system is legacy when it costs more to keep alive than it returns, when the people who understand it are leaving, or when it actively blocks the changes the business needs. A clean ten-year-old service that ships features weekly is not legacy. A two-year-old tangle that nobody dares touch already is.
Modernization covers a spectrum, and the word is often used loosely. Gartner and others describe a range of options, but for decision-making it helps to collapse them into four practical moves.
The three patterns in this article's title sit mostly inside refactor and replace. Strangler fig and incremental migration are how you execute a refactor or rebuild safely. Big bang is how a replacement goes wrong when teams underestimate the system they are killing.
Martin Fowler named the strangler fig pattern after the vine that germinates in a tree's canopy, sends roots to the ground, and gradually envelops its host until the original tree dies and the fig stands in its place [3]. Applied to software, you build new functionality around the edges of the legacy system, route traffic to the new code piece by piece, and shrink the old system until nothing is left to retire.
The mechanism is an interception layer. You place a facade, proxy, or routing layer in front of the legacy system. Each request is checked: if the function has been migrated, it goes to the new service, otherwise it falls through to the old one. Over months, you flip routes one at a time. Both systems run in parallel until the last route moves.
Strangler fig is not free. You run and pay for two systems at once, sometimes for a long time. The interception layer adds latency and a single point of failure if you build it carelessly. Shared data is the real test: when both old and new code read and write the same records, you need a clear strategy for synchronisation, dual writes, or change data capture. Without that, you corrupt data instead of migrating it.
The pattern also demands seams. If the legacy code has no clear boundaries between functions, you cannot intercept and route cleanly. Part of the early work is often carving seams into a monolith before any traffic moves. Teams like Mind Supernova that take on modernization work usually spend the first weeks finding and instrumenting those seams rather than writing new features.
Big bang means building the replacement in full, then switching from old to new in one planned event. The appeal is obvious: one clean system, no awkward period of running two, no interception layer, and a clear finish line. For a small, well-understood system with a hard deadline (a vendor sunsetting a product, for example), a controlled big bang can be the right and even the cheapest call.
The danger is equally obvious once you have lived through one. You deliver no value until cutover day, which may be 18 to 30 months away. The legacy system keeps changing during the build, so you are aiming at a moving target. The cutover itself is all-or-nothing: if it fails, rollback may be impossible because data has already migrated and users have already switched. Many large public rewrites have failed precisely here.
If you cannot tick most of those boxes, big bang is a bet, not a plan. The honest question to ask the board is whether the organisation can survive a failed cutover. If the answer is no, the strangler fig pattern is the responsible choice even though it looks slower on the slide.
Incremental migration is often listed as the third option, but it is better understood as the delivery model that powers strangler fig and de-risks replacement. The idea is simple: break the work into small, independently shippable slices, each of which leaves the system working and delivers something measurable. Strangler fig is a specific incremental pattern; incremental migration is the broader discipline.
You can run incremental migration without a full strangler facade. Common variants include migrating by module (extract one bounded context at a time), by data domain (move customers, then orders, then billing), or by user segment (route 5% of traffic to the new system, then 20%, then 100%). The unifying principle is that every increment is reversible and verifiable.
Pattern choice should follow the system, not the other way around. The framework below scores a system on the factors that actually predict success. Score each factor, weight it, and let the totals point you toward strangler fig, incremental modular extraction, or (rarely) a controlled big bang.
+---------------------------+
Client ---> | Routing / Facade Layer |
request +-------------+-------------+
|
migrated? | yes -----> [ New Service ] ---> [ New DB ]
| ^
| no -----> [ Legacy Monolith ] ---> [ Legacy DB ]
| |
+----- CDC sync keeps data consistent --+
Over time, more routes flip from "no" to "yes" until the
legacy monolith handles zero traffic and is decommissioned.
| Dimension | Strangler Fig | Big Bang | Incremental (modular) |
|---|---|---|---|
| Risk profile | Low: per-slice rollback | High: single point of failure at cutover | Low to medium: reversible slices |
| Time to first value | Weeks to a few months | End of programme only (often 18 to 30 months) | Weeks per slice |
| Total elapsed time | Longer (parallel running) | Shortest if it succeeds, infinite if it fails | Moderate, predictable |
| Cost shape | Higher run cost (two systems) | Lower run cost, higher risk cost | Steady, controllable |
| Rollback | Per route, instant | Often impossible after cutover | Per increment |
| Data handling | Sync or CDC during transition | One-time migration, high risk | Domain-by-domain migration |
| Best for | Large, critical, tightly coupled systems with reachable seams | Small, stable systems with hard deadlines | Systems with clear module boundaries |
| Worst for | Tiny systems where overhead exceeds benefit | Large, business-critical, evolving systems | Systems with no separable structure |
The core trade-off is speed of finish against safety of journey. Big bang optimises for a clean end state and the lowest steady-state cost, at the price of the highest risk and the longest wait for any value. Strangler fig inverts that: you accept higher running cost and a longer total timeline in exchange for continuous value, contained risk, and the ability to stop or change direction at any point.
There is a second trade-off that teams underestimate: cognitive load. Running two systems plus an interception layer plus data sync is more to operate and reason about than either system alone. That overhead is real and ongoing. The strangler fig pattern only pays off when the migration is large enough that the safety it buys outweighs the complexity it adds. For a genuinely small system, that overhead can exceed a careful big bang, which is exactly why size sits high in the framework.
The most instructive lesson in this space is not a single famous project but a repeated pattern that Fowler and others have documented for two decades [3]. The strangler fig pattern itself grew out of observing that full rewrites of large systems failed often enough to be predictable, while teams that grew a new system around the old one shipped steadily and rarely collapsed.
A concrete architectural lesson comes from the cloud-native era. When teams over-decompose during modernization, they trade one problem for another. Amazon's Prime Video team famously moved an audio and video monitoring service from a distributed serverless and microservices design back toward a consolidated monolith in 2023, reporting a cost reduction of more than 90% for that workload. The lesson for modernization is direct: the goal is the right architecture for the workload, not the maximum number of services. Strangling a monolith into 200 microservices can recreate every problem you set out to solve, now distributed across a network.
Put the two lessons together. Migrate incrementally so you never bet the business on a single cutover, and target a pragmatic end state (a well-factored modular monolith or a small set of services) rather than maximal decomposition. For deeper architecture guidance on that target state, see the sibling article on web application architecture in 2026, and for the runtime foundation, cloud-native application development.
A modernization programme that cannot show value every quarter will lose its funding before it finishes. Structure the work in 90-day increments, each ending with something measurable: a retired component, a migrated domain, a cost line that fell. The phases below assume a strangler fig or incremental approach, which is the right default for most enterprises.
Most failures are not technical surprises. They are predictable management and sequencing errors. These are the ones we see most often.
Legacy maintenance consumes a large share of most enterprise IT budgets (industry estimate), which is why the strongest business case for modernization is usually about freeing future capacity rather than cutting today's bill. If your engineers spend 60% of their time keeping an old system alive, the prize is redirecting that time to revenue work, not a smaller hosting invoice.
The cost shapes differ sharply by approach. Big bang concentrates spend into a build phase and promises the lowest steady-state cost, but carries a large unpriced risk cost: the expected value of a failed cutover. Strangler fig spreads spend over a longer timeline and adds the running cost of two systems plus the interception layer, but its risk cost is far lower because each slice is reversible.
| Cost factor | Strangler Fig | Big Bang | Incremental (modular) |
|---|---|---|---|
| Upfront build cost | Moderate, spread over time | High, concentrated | Moderate, spread over time |
| Parallel running cost | High (two systems + facade) | None | Low to moderate |
| Risk cost (failure expectation) | Low | High | Low to medium |
| Time to cost recovery | Gradual, starts early | Only after successful cutover | Gradual, starts early |
| Funding profile | Predictable, defensible quarterly | Large lump, hard to defend if delayed | Predictable |
| Hidden cost | Operational complexity of two systems | Lost edge cases, rework after failure | Coordination across slices |
Whatever the approach, build the business case in capacity and risk terms the board understands, and revisit it at the end of every phase. A programme that reports "two more domains migrated, 1.5 engineers of capacity freed" each quarter keeps its funding. One that reports "still building" does not.
Before committing to any custom modernization, test whether you should be writing code at all. The build-versus-buy decision for legacy systems has three real options, not two.
On the build side, the bottleneck is rarely strategy. It is senior engineers who can read an undocumented legacy system, find its seams, and migrate it without breaking it. That scarce skill is why many enterprises bring in a software engineering partner for the heavy lifting. A team like Mind Supernova, a Vietnam-based engineering partner founded in 2023, can stand up senior engineers in 5 to 7 days with 4+ hours of daily UK overlap, working async-first against the increment-by-increment delivery model this work demands. Whether through staff augmentation to add capacity to your own team or a dedicated team owning a workstream, the model fits the phased, reversible nature of modernization. If you want to pressure-test your approach, you can schedule a call with our engineering team.
For the deeper technical playbook on a specific stack migration, the sibling article on PHP to Go migration walks through strangler fig in concrete code terms. For programmes where AI is part of the target state, the enterprise AI stack and the enterprise AI transformation roadmap show how modernization and AI adoption fit the same phased discipline.
It is a way to replace a legacy system gradually. You put a routing layer in front of the old system, build new functionality alongside it, and flip traffic from old to new one piece at a time until nothing of the old system is left. Martin Fowler named it after the strangler fig vine [3].
Occasionally. A controlled big bang can fit a small, stable, well-understood system facing a hard deadline, such as a vendor sunsetting a product, where running two systems in parallel is impossible. For large or business-critical systems, the lack of a rollback path makes it too risky to recommend as a default.
It depends on system size and approach, but plan for a programme measured in quarters and often years, not weeks. The key is to deliver measurable value every 90 days through incremental migration. A strangler fig programme runs longer in total than a big bang but starts returning value within the first few months.
Incremental migration is the broad discipline of shipping the work in small, reversible slices. Strangler fig is a specific incremental pattern that uses an interception layer to route traffic between old and new systems. You can migrate incrementally by module, data domain, or user segment without a full strangler facade.
Almost always migrate. A from-scratch rewrite discards the thousands of edge cases the legacy system has accumulated, and those edge cases are usually the actual business logic. Migrate behaviour incrementally and consider buying a product instead if the capability is a commodity rather than a differentiator.
Legacy modernization rewards patience and discipline. The strangler fig pattern is the safe default for large or critical systems because it contains risk, delivers value continuously, and lets you change direction at any point. Big bang is a narrow option for small, stable systems under a hard deadline. Incremental delivery is the engine underneath both. Use the decision framework to score your system on coupling, size, risk, data separability, deadline, and team knowledge, then let the result, not fashion, pick your path.
This quarter: map your legacy system, add observability, identify the seams, and price the business case in freed capacity rather than hosting savings. Next 90 days: stand up an interception layer, migrate one low-risk slice end to end, prove your rollback path, and report the capacity it frees. If you want senior engineers who can find the seams in an undocumented system and migrate it without breaking the business, talk to our engineering team.
Coding assistants are only the first step. Learn how AI-powered software development now spans the entire SDLC...

Agent-as-a-service (AaaS) sells completed work, not software seats. Here is how the SaaS-to-AaaS shift rewrite...

How to build a multi-tenant SaaS platform: tenancy models, tenant isolation, security, and billing, with archi...