
Agentic Workflows Explained: The Future of Intelligent Business Automation
What agentic workflows are, how they differ from RPA and simple LLM calls, the six core patterns, and a practi...
Bigger models do not fix bad data. Here is why high-quality training data drives AI performance, and how to build the pipelines and evals that deliver it.
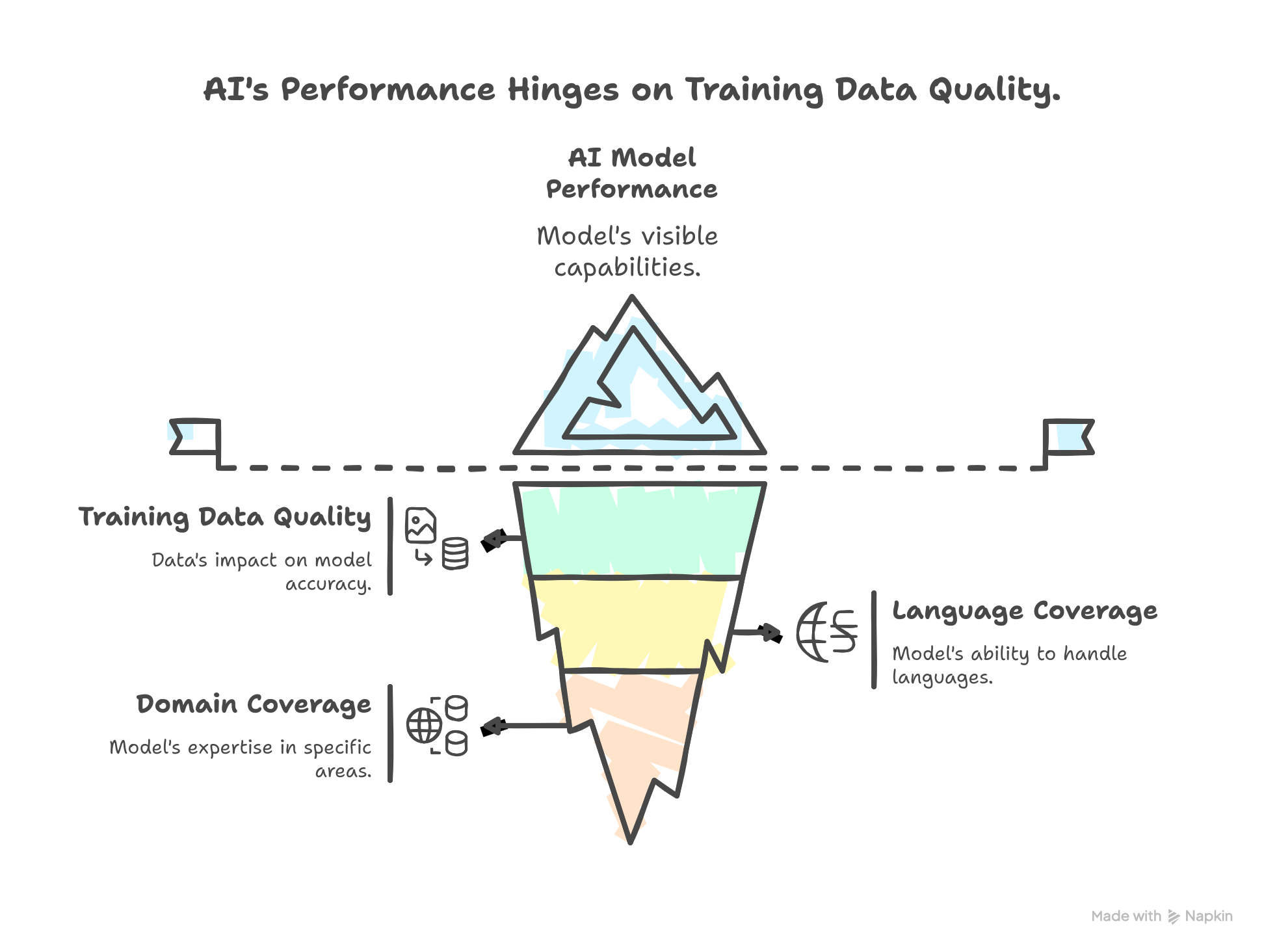
High-quality training data now matters more than raw model size because the largest gains in enterprise AI come from feeding models clean, well-labeled, representative data rather than from adding parameters. Frontier models are already commoditized: most enterprises rent the same handful of foundation models through an API. What separates a system that delivers measurable value from one that stalls in pilot is the quality, governance, and grounding of the data flowing through it.
That distinction explains a sobering result. Roughly 95% of enterprise generative-AI pilots show no measurable P&L return [1]. The models are rarely the bottleneck. The data, the evaluation discipline, and the workflow around them usually are. Around 70% of organizations report data difficulties as a barrier to scaling AI [2], and that single fact does more to predict success than any benchmark score.
This article makes the data-quality-over-scale case with evidence, then gets practical: how to build data pipelines, run annotation and evaluation programs, use synthetic data safely, and govern the whole thing. If your team is weighing a bigger model against a better dataset, the better dataset almost always wins.
Key Takeaways
If you're deciding where to spend your next AI budget cycle, a data audit and an evaluation framework will usually return more than a model upgrade. Schedule a call with our team to pressure-test your data strategy.
For a few years, the story of AI progress was scale: more parameters, more compute, better results. That story still holds at the research frontier, but it has stopped being where enterprise value is created. The reason is simple. The biggest models are available to everyone on roughly equal terms.
When your competitor can call the same model you can through the same API, the model isn't your advantage. Your proprietary data, your labeling standards, and your evaluation rigor are. Those are the assets a rival can't copy by signing up for an account.
The market has already voted with its architecture choices. RAG (retrieval-augmented generation) is now used in 51% of enterprise gen-AI deployments, up from 31%, while only about 9% of production models are fine-tuned [3]. Enterprises are choosing to ground a capable general model in their own curated data rather than spend on retraining. That is a direct bet on data over model weights. Our companion piece on enterprise RAG systems covers that architecture in depth.
There's a second reason. Generative-AI use has surged from 33% in 2023 to 71% in 2024 [5], so the technology is everywhere. Ubiquity erases differentiation. What you do with your data is what's left.
Larger models are more capable, but they're also more faithful amplifiers of whatever you feed them. A bigger model trained or grounded on inconsistent, biased, or stale data produces inconsistent, biased, or stale answers with greater fluency and confidence. Scale magnifies data quality in both directions. That makes clean data more valuable as models grow, not less.
The strongest argument for data over scale is the gap between AI activity and AI returns. Adoption is near-universal, yet financial impact is rare. That pattern points away from the model and toward everything surrounding it.
Consider the numbers. About 95% of enterprise gen-AI pilots show no measurable P&L return [1]. Only around 6% of firms qualify as AI "high performers" attributing 5% or more of EBIT to AI, and just 39% report any enterprise EBIT impact at all [4]. Roughly 74% of companies struggle to scale AI value, and only about 4 to 5% capture significant scaled value [6]. These are not model problems. The same models are available to the winners and the laggards.
Crucially, McKinsey finds that workflow redesign is the biggest driver of EBIT impact from AI [4]. Value comes from rewiring how work happens around reliable, well-grounded outputs, and reliable outputs require quality data and rigorous evaluation. A bigger model dropped into a broken workflow on top of messy data changes nothing.
| InvestmentTypical marginal valueWhy | ||
| Upgrading to a larger foundation model | Low to moderate, and easily matched by competitors | Same models are available to everyone via API |
| Cleaning and curating proprietary data | High and defensible | Directly improves grounding and reduces hallucination on your domain |
| Building a high-quality annotation program | High | Labels define what "good" means; quality compounds across models |
| Building rigorous evaluation / eval sets | Very high | You cannot improve or trust what you cannot measure |
| Workflow redesign around AI outputs | Highest reported EBIT driver [4] | Captures value where work actually happens |
Read the table top to bottom and the pattern is clear. The cheapest, most-copyable lever (a bigger model) sits at the bottom of the value ranking. The data and process levers sit at the top.
High-quality data isn't just "more data." It's data that meets specific, measurable properties. Treating quality as a checklist rather than a vibe is what turns a data effort into an engineering discipline.
Notice that several of these are governance properties, not statistical ones. Provenance and rights aren't about model accuracy at all, but they determine whether you can defend the system to a regulator or a customer. In modern AI, data quality and data governance are the same conversation.
A common mistake is chasing dataset size as a proxy for quality. A smaller dataset that covers your edge cases and matches your production distribution will usually outperform a larger one full of redundant, easy examples. Models learn from the hard, rare, ambiguous cases, and those are exactly the ones casual data collection misses.
A data pipeline turns messy, scattered raw inputs into evaluated, model-ready datasets. Each stage either adds quality or, if skipped, silently injects risk. Here's a practical sequence enterprises can follow.
The two stages teams skip most often are deliberate splitting and versioning. Skipping them feels harmless and quietly destroys your ability to trust any later measurement. Building a pipeline at scale is a discipline of its own, which we cover in building AI training data at scale.
Annotation is where humans tell the model what good looks like. Labels are the ground truth a model learns from or is evaluated against, so the quality ceiling of your system is set by the quality of your labels. You cannot out-model bad annotation.
This is why the data-labeling market is projected to grow from $3.77B in 2024 to $17.1B by 2030, a 28.4% CAGR [3]. As models commoditize, the human judgment encoded in labels becomes the scarce, valuable input. The market is pricing in exactly the thesis of this article.
This human-in-the-loop model is core to how an AI workforce combines human expertise with automation. It's also where an annotation partner earns its keep. Mind Supernova runs human-in-the-loop annotation teams precisely because label quality, not model choice, is where most enterprise AI projects are won or lost. Our deeper guide to data annotation services for generative AI walks through this in detail.
Evaluation is the single most underrated investment in enterprise AI. An eval set is a curated, held-out collection of inputs with known good outputs that you use to measure model behavior objectively. Without it, "the model seems better" is the best you can say, and that's not a basis for a production decision.
Good evaluation separates the teams that improve from the teams that guess. It tells you whether a prompt change, a new model, or a data refresh actually helped, and it catches regressions before customers do. For generative systems, evaluation is harder than classic accuracy metrics because outputs are open-ended, so most mature teams combine several methods.
Treat your eval set as a strategic asset. A well-built golden set is reusable across every model you'll ever try, which is exactly why it outranks any single model upgrade in long-term value.
Synthetic data is artificially generated data used to augment real datasets, fill coverage gaps, or protect privacy. Used well, it's a genuine accelerator: you can generate rare edge cases, balance underrepresented classes, and create training material without exposing sensitive records. It is one of the most practical ways to improve representativeness when real data is scarce.
Used carelessly, it's a trap. The main risk is model collapse: when models are trained heavily on their own or other models' outputs, errors and narrowness compound, and quality degrades over generations. Synthetic data can also bake in the biases of the model that generated it while looking superficially clean.
Data governance is the set of policies, roles, and controls that keep your data accurate, secure, compliant, and traceable. In modern AI it's inseparable from quality, because an unverifiable dataset is a liability no matter how accurate it looks. Governance is also increasingly a legal requirement, not a nice-to-have.
The regulatory backdrop is concrete. The EU AI Act has been in force since August 2024, with prohibited-practices and AI-literacy duties applying since February 2025 and general-purpose AI obligations since August 2025 [8]. The Act places specific data-governance and data-quality obligations on high-risk systems, so your training data is now in scope of regulation, not just engineering. Note that under the provisional Digital Omnibus (as of mid-2026), some high-risk Annex III obligations are expected to be deferred to December 2027; confirm against the final text.
Two established frameworks help you operationalize this. The NIST AI Risk Management Framework (1.0, 2023, with a 2024 Generative AI Profile) gives you a structure for identifying and managing data and model risk [9]. ISO/IEC 42001:2023 provides a certifiable AI management system standard. Mapping your data governance to one of these turns "we try to be careful" into an auditable program.
Consider a composite example drawn from our team's collective experience: a global software company wanting to automate tier-one customer support with a gen-AI assistant. Their first attempt used a top-tier foundation model with light prompt engineering. It hallucinated product details, contradicted policy, and the pilot showed no measurable savings, the same outcome 95% of pilots report [1].
The fix was not a bigger model. It was a data overhaul. The team built a clean, deduplicated knowledge base from verified help-center and policy documents, grounding the assistant with RAG instead of trusting model memory. They ran a structured annotation pass on 4,000 historical tickets to define correct resolutions, then built a golden eval set of 500 real, hard queries with verified answers.
With those data foundations, they measured every change against the eval set and redesigned the support workflow so the assistant drafted responses for human approval. Accuracy on the golden set rose steadily, hallucinations on policy questions dropped sharply, and the workflow redesign, the biggest EBIT driver per McKinsey [4], turned the pilot into a deployed system. The model was the same. The data and the process were different.
Bad data is expensive in ways that don't show up on the AI line item. The 95% of pilots with no P&L return represent enormous sunk cost in engineering time, cloud bills, and opportunity [1]. But the deeper costs accumulate after deployment.
The throughline is that bad data doesn't fail loudly. It fails quietly and confidently, which is why the cost is so often discovered late.
If data quality is so clearly the lever, why don't more enterprises pull it? Because the obstacles are organizational and unglamorous, not technical mysteries. Naming them is the first step to budgeting for them.
This is where specialized help changes the economics. Building an in-house annotation and data-engineering team is slow and expensive. An AI engineering partner can supply vetted senior engineers who start in 5 to 7 days and human-in-the-loop annotation workforces, with async-first delivery and 4+ hours of daily UK overlap. Mind Supernova, a Vietnam-based AI engineering company founded in 2023, is one option among several for organizations that want to stand up serious data pipelines, annotation programs, and evaluation frameworks without an 18-month hiring cycle. Our broader AI development services and staff augmentation exist precisely for this gap.
Here's a sequence any enterprise can follow to put data ahead of model size in practice. The order matters: measurement before modeling, foundations before scale.
These priorities connect directly to the broader shifts in our overview of the top AI trends transforming enterprise growth in 2026, where efficient models and data quality consistently outrank raw scale.
Yes, but with diminishing returns for most enterprises. A capable model is necessary, but once you have one, additional scale rarely beats better data. Since the same large models are available to everyone via API, your proprietary data, annotation quality, and evaluation rigor are what create durable, defensible advantage.
An eval set is a curated, held-out collection of inputs with known correct outputs used to measure model behavior objectively. You need one because you cannot improve or trust what you cannot measure. It lets you compare models, catch regressions, and prove that a change actually helped before shipping it.
It's safe when used to augment, not replace, real data. Synthetic data is excellent for filling coverage gaps and protecting privacy, but training too heavily on generated data risks model collapse, where quality degrades over generations. Always validate synthetic examples against real ground truth and keep your test set real and human-verified.
Start with RAG for most use cases. Retrieval-augmented generation grounds a general model in your curated data and is now used in 51% of enterprise deployments, versus about 9% that fine-tune [3]. RAG is cheaper, easier to update, and keeps data fresh. Fine-tune only when you need behavior RAG cannot provide.
The EU AI Act, in force since August 2024, places data-governance and data-quality obligations on high-risk AI systems, so your training data is now in regulatory scope [8]. You need documented provenance, rights, bias testing, and lineage. Mapping your governance to NIST AI RMF or ISO 42001 helps you meet these obligations defensibly.
The enterprises winning with AI in 2026 aren't the ones with the biggest models. They're the ones with the cleanest data, the sharpest eval sets, and the discipline to measure before they ship. Model size is a commodity. Data quality, annotation rigor, and governance are the assets competitors can't copy.
This week: run a quick data audit on your highest-priority AI use case and start a golden eval set from real production queries. This quarter: stand up an annotation program, ground your system with RAG on clean data, and map your governance to NIST AI RMF or ISO 42001.
If you want experienced help building data pipelines, annotation programs, or evaluation frameworks, Mind Supernova provides AI engineering teams and human-in-the-loop annotation workforces, with senior engineers who start in 5 to 7 days and 4+ hours of daily UK overlap. Schedule a call to map your data-first AI roadmap.
What agentic workflows are, how they differ from RPA and simple LLM calls, the six core patterns, and a practi...

How enterprises are moving from AI copilots to AI employees: autonomous digital workers that own a scoped role...

What is an AI operating system? A clear, practical guide to the AI OS concept, its enterprise layers, the LLM-...