? The Enterprise AI Standard Explained for 2026")
What Is MCP (Model Context Protocol)? The Enterprise AI Standard Explained for 2026
What is MCP? A clear, technical guide to the Model Context Protocol — the open standard that connects AI apps...
RAG grounds AI in your own data for accuracy and security. Learn the architecture, RAG vs fine-tuning, and how to deploy it in the enterprise.
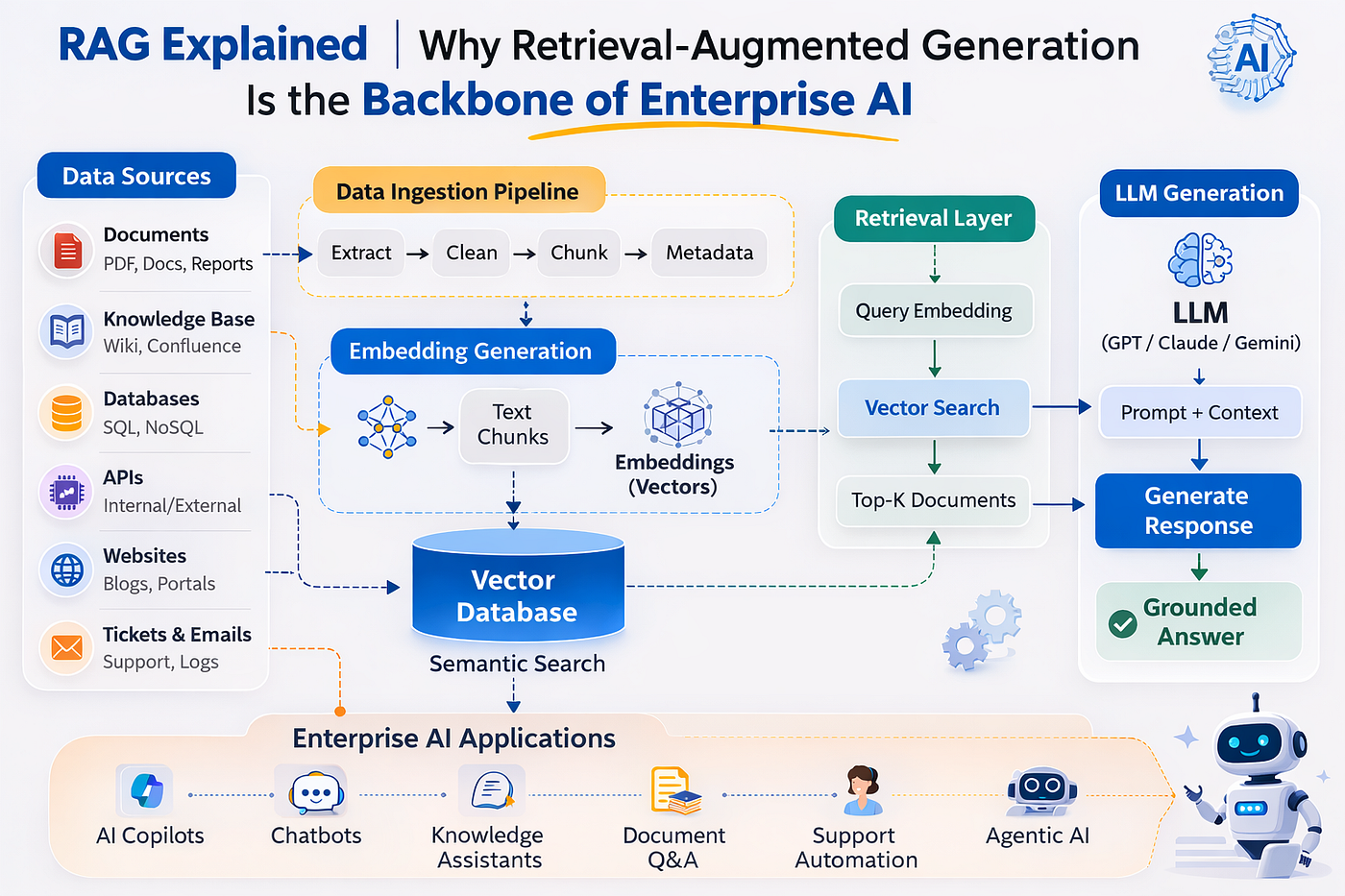
Enterprise RAG (retrieval-augmented generation) is the architecture that lets a large language model answer from your own approved, current, access-controlled data instead of guessing from its training set. That single shift is why RAG has become the default pattern for serious business AI: it grounds answers in source documents, cuts hallucinations, and keeps sensitive data inside your control boundary. Menlo Ventures found RAG already powered 51% of enterprise generative-AI deployments in 2024, up from 31% the year before, while only about 9% of production models were fine-tuned [1].
The reason is practical. A base model knows nothing about your contracts, your product catalog, your support history, or last quarter's policy change. RAG fixes that without retraining a model. It retrieves the right passages at query time and hands them to the model as grounded context, so the output reflects facts you can trace to a source.
This guide explains the architecture end to end (chunking, embeddings, vector databases, retrieval, and grounding), the security model that makes RAG enterprise-safe, how it reduces hallucinations, when to choose RAG over fine-tuning, and how to implement it without stalling. If you are weighing where to invest, our team at Mind Supernova builds these systems for global clients, and you can schedule a call to pressure-test your approach.
Key Takeaways
Retrieval-augmented generation is a pattern, not a product. Instead of asking a model to recall an answer from its frozen training data, you first search a knowledge base for the most relevant passages, then pass those passages to the model along with the user's question. The model composes an answer using the retrieved evidence. The knowledge stays external, fresh, and governed.
That design matters because the gap between AI pilots and AI value is brutal. MIT's Project NANDA reported that roughly 95% of enterprise generative-AI pilots delivered no measurable profit-and-loss return [5]. A large share of those failures come from ungrounded outputs that business users cannot trust. RAG attacks the trust problem directly by making every answer traceable to a citable source.
It also matters for currency. Models are trained to a cutoff date. Your business is not. When pricing changes, a policy updates, or a new product ships, a RAG system reflects it the moment the document lands in the index. No retraining cycle, no waiting for the next model release. For an overview of how retrieval fits alongside agentic systems and multimodal AI, see our companion piece on the top AI trends transforming enterprise growth in 2026.
A production RAG system is a pipeline. Each stage has its own failure modes, and skipping the engineering on any one of them is how teams end up with a demo that impresses and a system that disappoints. Here is the full path from raw document to grounded answer.
Documents arrive as PDFs, wiki pages, tickets, contracts, and database rows. You parse them into clean text, then split that text into chunks. Chunk size is a real design decision: too large and retrieval pulls in noise that dilutes the prompt, too small and you sever the context a passage needs to make sense. Most enterprise systems land between 256 and 1,024 tokens per chunk with some overlap, then tune from there.
Smart chunking respects structure. Splitting on headings, sections, or semantic boundaries preserves meaning far better than a blind character count. Each chunk also carries metadata: source document, section, author, date, and (critically) access-control tags.
Each chunk is converted into a vector, a numeric representation of its meaning, using an embedding model. Passages with similar meaning land near each other in vector space, which is what makes semantic search work. A question about "termination clauses" can retrieve a chunk that says "ending the agreement" even with no shared keywords. The choice of embedding model, and whether it understands your domain language, has a large effect on retrieval quality.
The vectors and their metadata live in a vector database such as Pinecone, Weaviate, Qdrant, Milvus, or pgvector inside Postgres. The database indexes vectors for fast approximate-nearest-neighbor search across millions of chunks. Enterprise requirements here include metadata filtering, hybrid search, multi-tenancy isolation, and the ability to enforce access control at query time.
At query time, the user's question is embedded and the database returns the top matching chunks. The best systems use hybrid retrieval, combining semantic (vector) search with keyword (BM25) search, because each catches what the other misses. A reranking step then reorders candidates by true relevance before they reach the model. Retrieval quality is the single biggest lever on RAG accuracy.
The retrieved chunks are inserted into the prompt as context, with an instruction telling the model to answer only from that context and to cite sources. This is grounding. When the model has the right evidence in front of it and is told to stay within it, hallucinations drop sharply and answers become auditable. If retrieval returns nothing relevant, a well-designed system says so rather than inventing an answer.
RAG's biggest enterprise advantage is structural. Your knowledge never enters the model's weights. It stays in a database you own and govern, retrieved only when authorized. That separation is what lets regulated organizations adopt generative AI at all.
The non-negotiable control is permission-aware retrieval. The system must filter results by the requesting user's access rights before anything reaches the model. If a sales rep cannot open a legal contract in your document store, the RAG system must never retrieve a chunk from it. Bolting authorization on after retrieval is a leak waiting to happen; it belongs in the query filter itself.
Treat the OWASP Top 10 for LLM Applications (2025) as your threat checklist [6]. Prompt injection ranks first: a malicious instruction hidden inside a retrieved document can hijack the model's behavior, so retrieved content must be sanitized and treated as data, not commands. Sensitive-information disclosure is another top risk, which is exactly what permission-aware retrieval and metadata governance are built to prevent.
Wrap the whole system in a recognized framework. The NIST AI Risk Management Framework and its Generative AI Profile give you a structure for mapping, measuring, and managing risk [7], while EU AI Act obligations apply depending on use case and risk tier [8]. Logging matters too: capture every query, every retrieved source, and every answer so you have an audit trail. For the broader control set, see our sibling article on AI governance, security and compliance strategies for 2026.
A hallucination is a confident answer with no factual basis. Base models hallucinate because they generate the most probable next words, not the most truthful ones. RAG changes the inputs: when the model is handed verified, relevant passages and instructed to answer only from them, it has real evidence to work with and far less room to invent.
Citations close the loop. Because each answer traces back to specific retrieved chunks, a user can verify the claim, and a reviewer can audit it. That traceability is the difference between an AI that business teams quietly stop using and one they rely on. It is also what makes RAG defensible in regulated reviews.
Accuracy in RAG is mostly an engineering problem upstream of the model. The common culprits are predictable, and so are the fixes.
You cannot improve what you do not measure. Run a structured evaluation set that scores retrieval (did the right chunk come back?) and generation (was the answer faithful to the source?). High-quality evaluation depends on well-labeled examples, which is where a human-in-the-loop data workforce earns its keep; our article on why high-quality training data matters more than model size goes deeper on that discipline.
RAG and fine-tuning are often framed as rivals. They are not. RAG injects knowledge at query time; fine-tuning bakes behavior, tone, and format into the model through additional training. They answer different questions, and many strong systems use both: RAG for the facts, a fine-tuned model for the style and structure of the response.
| DimensionRAG (retrieval-augmented generation)Fine-tuning | ||
| Primary purpose | Inject current, specific knowledge | Shape behavior, tone, and output format |
| Data freshness | Live; update the index, see it instantly | Frozen at training time; needs retraining |
| Knowledge location | External database you own and govern | Inside model weights |
| Access control | Enforced at retrieval per user | Hard; knowledge is baked in for everyone |
| Source traceability | Strong; answers cite documents | Weak; no built-in provenance |
| Setup and change cost | Lower ongoing; update documents only | Higher; training runs and data prep per change |
| Best for | Knowledge that changes often, needs citations and permissions | Consistent style, domain phrasing, structured output |
| 2024 production usage | 51% of deployments [1] | ~9% of production models [1] |
The decision rule is simple. If the problem is "the model does not know our facts," reach for RAG. If the problem is "the model does not answer in our voice or format," reach for fine-tuning. For nuanced domain behavior layered on top of grounded facts, combine them. Our explainer on LLM fine-tuning services explained covers when the training investment pays off, and the broader strategic split between these capabilities is unpacked in generative AI vs agentic AI.
Consider a B2B software company with thousands of help articles, product manuals, release notes, and a decade of resolved support tickets. Agents waste time hunting across systems, answers drift out of date, and customers get inconsistent guidance across regions. Fine-tuning a model on all of it would be expensive, would freeze the knowledge the day training ended, and would offer no way to enforce who can see what.
A RAG assistant solves this cleanly. Every article, manual, and ticket is chunked, embedded, and indexed with metadata for product line, region, and entitlement tier. When an agent asks a question, the system retrieves the most relevant current passages, filters them by the customer's plan and the agent's access, and the model composes a grounded answer with citations the agent can click to verify.
The payoff is concrete. New release notes appear in answers the day they publish, with no retraining. Sensitive enterprise-tier documentation never surfaces for an agent serving a lower tier. And because every answer is sourced, supervisors can audit accuracy instead of trusting a black box. This is the same retrieval foundation that more autonomous systems build on; once answers are reliable and permissioned, the assistant can graduate toward action-taking, a path we explore in how AI agents are replacing traditional software workflows.
A working RAG system is less about a clever model and more about disciplined engineering across the pipeline. Here is a sequence that keeps projects out of the pilot graveyard.
This blends data engineering, ML engineering, security, and ongoing human evaluation. Many enterprises do not have all of those skills on the bench, which is why teams partner for delivery. Mind Supernova combines AI engineering with a human-in-the-loop data and annotation workforce, and works async-first with at least 4+ hours of daily UK overlap, with vetted senior engineers who can start in 5 to 7 days. We are one credible option among several; our experience building these pipelines is covered in AI development services in Vietnam, and our broader AI development services page outlines how we staff projects.
RAG is well understood, but enterprise-scale deployment still trips teams up. The failures are rarely about the model. They are about data, retrieval quality, security, and operations.
Stale, duplicated, contradictory, or poorly permissioned documents degrade every answer. With roughly 70% of organizations reporting data difficulties [2], the index is only as trustworthy as the corpus behind it. Address it with source-of-truth ownership, deduplication, freshness rules, and access tags applied at ingestion.
If the correct chunk does not surface, the model cannot use it. Plain vector search alone often underperforms. Address it with hybrid retrieval, reranking, and chunking tuned to your content rather than copied from a tutorial.
Retrieved documents can carry hidden malicious instructions, the OWASP number-one LLM risk [6]. Address it by treating retrieved content as untrusted data, sanitizing inputs, enforcing permission-aware retrieval, and logging everything for audit.
Embedding millions of chunks, running reranking, and serving large prompts adds compute cost and response time. Address it with caching, right-sized models for each step, retrieving fewer high-quality chunks, and monitoring cost per query as a first-class metric.
With about 95% of generative-AI pilots showing no measurable P&L return [5], leadership rightly demands evidence. Address it by tying the system to a measurable outcome (resolution time, deflection rate, hours saved) and reporting against it from the pilot onward.
Enterprise RAG is a method where an AI model first searches your company's own approved documents for relevant information, then uses those passages to write an answer. It keeps responses grounded in current, permissioned data you control, rather than relying on the model's frozen training knowledge.
RAG sharply reduces hallucinations but does not eliminate them. By grounding answers in retrieved source documents and instructing the model to cite them, it gives the model real evidence to work from. Strong retrieval, grounding guardrails, and evaluation are still required to keep accuracy high.
Choose RAG when the model needs current, specific knowledge with citations and access control. Choose fine-tuning when you need consistent tone, domain phrasing, or structured output. They are complementary, and many enterprise systems combine RAG for facts with a fine-tuned model for response style and format.
Yes, when engineered correctly. RAG keeps sensitive data in a database you govern rather than in model weights, and permission-aware retrieval filters results per user. Pairing that with OWASP LLM controls, NIST AI RMF practices, and full audit logging makes RAG suitable for regulated, security-sensitive environments.
A focused pilot on a bounded use case typically takes a few weeks once data access is sorted; production hardening with security, evaluation, and scale takes longer. The slowest part is usually data preparation, since around 70% of organizations report data difficulties [2], not the model integration itself.
RAG has become the default architecture for trustworthy business AI because it solves the three problems that sink generative-AI projects: stale knowledge, hallucinations, and data control. It grounds answers in your own current, permissioned sources and makes every response traceable. With RAG already in 51% of enterprise deployments [1] and most pilots still failing to show returns [5], disciplined retrieval engineering is the difference between AI that ships value and AI that stalls.
This week: pick one bounded, high-value use case and audit the documents behind it for quality and access rules. This quarter: build a permission-aware RAG pilot with hybrid retrieval, grounding guardrails, and a real evaluation set, then measure it against one business outcome before you scale.
If you want experienced help designing or building it, Mind Supernova pairs AI engineering with a human-in-the-loop data workforce and senior engineers who start in 5 to 7 days. Schedule a call to map your RAG architecture and turn a pilot into production.
What is MCP? A clear, technical guide to the Model Context Protocol — the open standard that connects AI apps...

A practical reference architecture for the agentic era: how AI agents and MCP turn brittle point-to-point inte...

Context engineering is the discipline of curating everything an AI agent sees at inference time. Here is why i...