
Enterprise AI Transformation Roadmap: From Pilot Projects to Enterprise-Scale AI Adoption
A phased enterprise AI transformation roadmap that takes you from pilot purgatory to enterprise-scale adoption...
A build-it framework for an AI center of excellence: operating models compared, charter and roles, the capabilities it owns, funding, a phased roadmap, KPIs, and pitfalls.
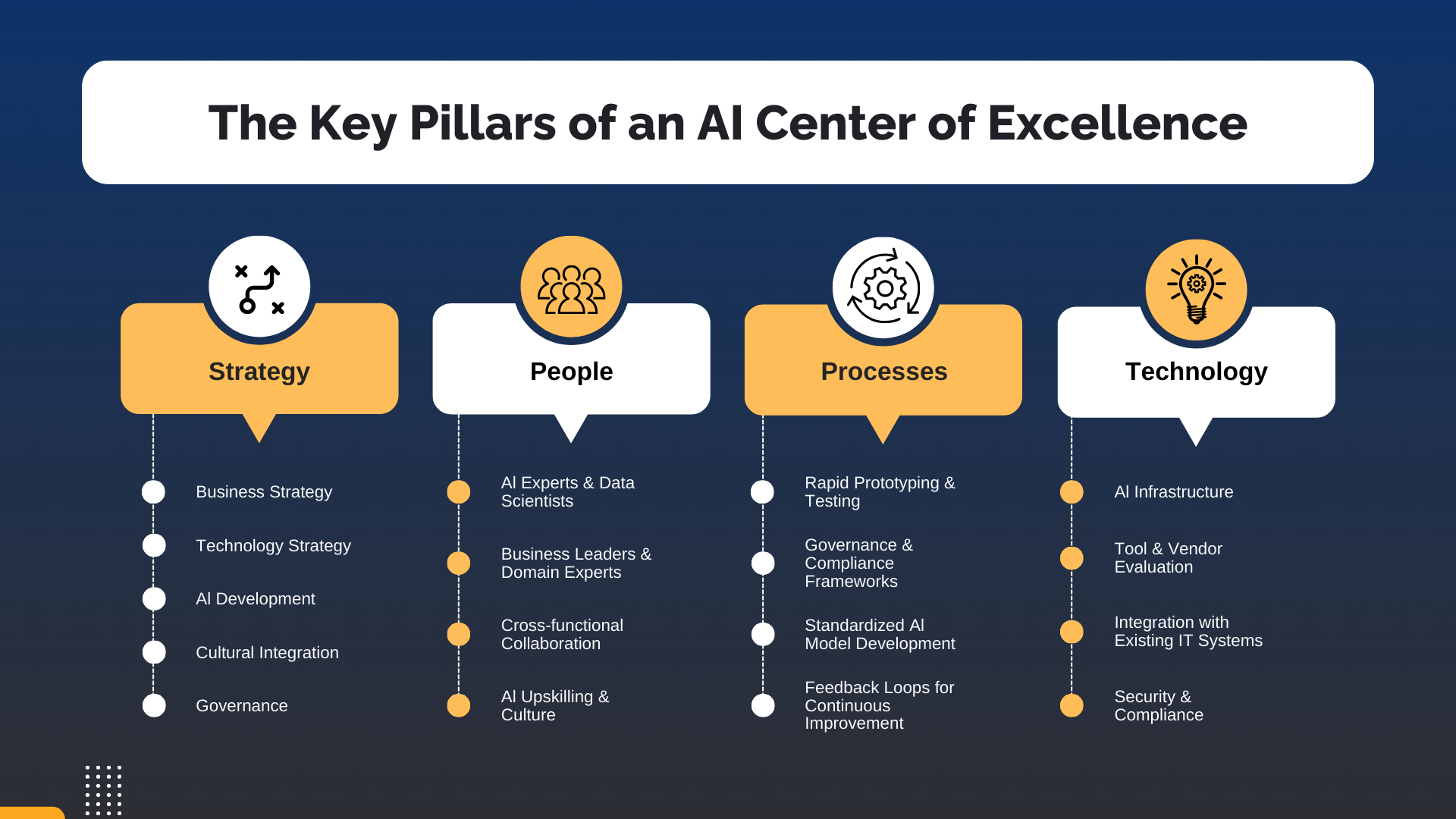
An AI center of excellence (AI CoE) is a dedicated, cross-functional team that sets the standards, platforms, governance, and talent practices an enterprise needs to deliver artificial intelligence reliably and at scale. Instead of letting every business unit reinvent its own approach to models, data pipelines, security reviews, and vendor selection, the CoE concentrates the scarce expertise and shared infrastructure in one place, then makes it reusable everywhere.
The reason the model has spread so quickly is simple: most enterprises do not have an AI ideas problem. They have a scaling problem. Pilots accumulate, budgets get spent, and very little reaches durable production. Industry surveys through 2025 consistently described the same pattern, with the majority of AI proofs of concept never graduating to enterprise scale. A well-designed CoE exists to break that pattern by turning one-off projects into a repeatable production capability.
This article is a practical, build-it framework rather than a definition piece. It walks through the operating models you can choose from, how to write a CoE charter that actually carries authority, the roles you need to hire or borrow, the capabilities the CoE should own, how to fund it, a phased stand-up roadmap, the KPIs that prove it is working, and the pitfalls that quietly turn a promising CoE into either an ivory tower or a bottleneck. If you are designing where AI sits in your organization, this is the operating-model decision you make once and live with for years.
Key Takeaways
An AI center of excellence is the operating structure that integrates the people, processes, and technology required to scale AI across an enterprise. In practice it acts as a shared service: it builds the platforms teams reuse, codifies the standards they follow, runs the governance that keeps the organization out of trouble, and develops the talent that makes AI a durable capability rather than a series of disconnected experiments.
The need arises from a structural problem. AI delivery requires a rare combination of skills (data engineering, machine learning, MLOps, security, domain knowledge, change management) that no single business unit can staff economically. Without a coordinating function, the same problems get solved repeatedly and inconsistently: three teams build three different feature stores, two procure overlapping vendors, none can pass a security review on the first try, and nobody can answer how a given model makes its decisions when a regulator asks.
A CoE addresses this by amortizing expertise and infrastructure across the whole organization. IBM frames the CoE as a centralized team that brings together cross-functional expertise to accelerate adoption while keeping it responsible and aligned to business goals (IBM). Gartner has repeatedly noted that as enterprises shift from experimenting with AI to operationalizing it, those without a strategic coordinating framework tend to stall. The CoE is the most common answer to that coordination gap.
Crucially, a CoE is not the same thing as an AI strategy, and it is not a synonym for "the AI team." The strategy decides where to compete with AI; the CoE is the machine that makes delivery repeatable. If you are still working out the sequence from pilots to scaled adoption, the CoE is one component of a broader enterprise AI transformation roadmap, not a substitute for it.
The operating model defines who owns AI delivery and who sets the rules. There are three archetypes, and the right one depends on your size, regulatory exposure, and AI maturity. For most large, complex enterprises, the federated hub-and-spoke model is the strongest default because it combines shared infrastructure with business-unit ownership of outcomes.
In a centralized model, a single team builds and runs all AI initiatives. It maximizes consistency and control and is the easiest way to enforce standards early, which is why many organizations start here. The risk is that the central team becomes a queue: business units wait in line, lose context, and disengage. In a decentralized model, each business unit owns its own AI work end to end. This maximizes speed and domain relevance but produces duplicated effort, inconsistent governance, and fragile, unsupportable systems. The federated hub-and-spoke model is the hybrid: a lean central hub sets standards, governance, guardrails, shared platforms, and FinOps, while business-unit "spokes" build and own use cases on that shared foundation. This pattern consistently outperforms pure centralization in large organizations because it pairs the efficiency of shared infrastructure with the contextual intelligence of the people closest to the problem.
| Dimension | Centralized | Decentralized | Federated (Hub-and-Spoke) |
|---|---|---|---|
| Who delivers | One central AI team | Each business unit independently | Hub sets standards; spokes build use cases |
| Speed to deliver | Slows as demand grows (queue forms) | Fast locally | Fast once platforms exist |
| Standards & governance | Strong and consistent | Weak and inconsistent | Strong central standards, local execution |
| Domain relevance | Can drift from the business | High | High |
| Duplication of effort | Low | High | Low |
| Main failure mode | Bottleneck | Fragmentation and risk | Hub overreach if it tries to build everything |
| Best fit | Early maturity, small org, high-risk start | Highly autonomous, low-risk environments | Most large, multi-unit enterprises |
A practical sequence many enterprises follow is to start centralized to establish discipline (roughly the first 6 to 12 months), evolve into hub-and-spoke as platforms and standards mature and AI champions are embedded in business units, and over time move toward more autonomous federated pods sustained by central governance. The operating-model choice is not permanent, but it should be deliberate. Drifting into decentralization by neglect is how you end up with the fragmentation a CoE was meant to prevent.
A charter is the document that gives the CoE its authority, and it is the single most underrated determinant of success. Without one, the CoE becomes either a bottleneck because it tries to own everything, or an irrelevant advisory body because nobody is compelled to follow its guidance. The charter should be short, signed by an executive sponsor, and explicit about decision rights.
A workable charter answers five questions:
The authority question deserves the most attention. A useful pattern is a tiered mandate: the CoE has approval authority over anything that touches regulated data, customer-facing decisions, or material risk, and an advisory or enabling role for lower-risk, internal-productivity use cases. This lets the CoE govern what matters without becoming a gate on every experiment. The charter should also name the executive sponsor explicitly. A CoE without a CIO, CTO, or Chief Data and AI Officer standing behind it has no leverage when a powerful business unit decides to ignore the standards.
An effective AI CoE is deliberately cross-functional, spanning technical depth, business alignment, governance, and change management. The size scales with the enterprise, but the role archetypes are consistent. For a large enterprise, a federated model with a central team of roughly 8 to 15 people plus embedded AI leads in major business units is a common and effective shape.
Core central-hub roles typically include:
In the spokes, the most important role is the embedded AI lead (sometimes called an AI champion): a person inside a business unit who understands both the domain and the CoE's platforms and standards, and who acts as the two-way bridge. These embedded roles are what keep the hub honest and prevent the ivory-tower problem, because they carry real operational feedback back to the center.
Not every role needs a permanent full-time hire. Legal, security, finance, and HR should be represented through a steering or advisory body rather than absorbed into the team. And because the specialized talent (especially MLOps and applied ML engineering) is genuinely scarce, many enterprises blend internal hires with an external delivery partner to stand the capability up faster, supplying the MLOps and applied-AI engineering muscle while internal leaders own the strategy, governance, and domain context. Whether you build, borrow, or blend, the key is that the CoE owns the standards even when others do some of the building. For more on structuring the human-and-machine side of delivery, see our guide to AI workforce solutions that blend human expertise with intelligent automation.
The CoE earns its budget by owning the capabilities that are wasteful or risky to duplicate across business units. Five capability areas form the core of a practical AI CoE framework.
This is the capability that justifies a CoE on its own. The CoE defines how AI is reviewed, approved, monitored, and decommissioned, and maps those controls to recognized frameworks rather than inventing its own from scratch. The NIST AI Risk Management Framework provides a structure (Govern, Map, Measure, Manage) for identifying and mitigating AI risk, while ISO/IEC 42001 offers a certifiable AI management system standard. For enterprises serving European markets, the EU AI Act introduces risk-tiered obligations the CoE should track. Gartner has emphasized that effective governance blends IT, risk, and data governance rather than treating AI as a silo (Gartner). A note of nuance worth designing for: governance should be proportionate to risk. Applying one heavy, uniform process to every use case, including low-stakes internal tools, is a reliable way to make the CoE a bottleneck.
The CoE builds and operates the shared technical foundation so spokes do not each rebuild it: feature stores, a model registry, CI/CD for models, deployment patterns, monitoring, evaluation harnesses, prompt and retrieval infrastructure for generative AI, and FinOps for managing inference cost. This is where reuse compounds fastest. None of it works without solid data foundations, which is why platform strategy and data strategy have to move together; see our deeper treatment of modern data platforms for AI-driven organizations.
The CoE codifies how things are done: approved tools and models, reference architectures, security and privacy patterns, evaluation criteria, and documentation standards. Good standards are accelerants, not paperwork. A spoke team should be able to start from a vetted reference architecture and a working template rather than a blank page.
The CoE develops the organization's AI capability through training, communities of practice, internal certifications, and embedded coaching. The goal is to raise the AI fluency of the whole enterprise, not to hoard expertise at the center. This is also where adoption is won or lost; the best model in the world delivers nothing if the people meant to use it never trust or adopt it.
The CoE runs a transparent intake and prioritization process so the organization invests in the highest-value, most feasible use cases rather than the loudest stakeholder's pet project. A simple value-versus-feasibility scoring model, applied consistently, keeps the portfolio honest and gives executives a defensible view of where AI spend is going.
Funding model is a strategic choice that shapes behavior, not just an accounting detail. There are three common approaches, and many enterprises evolve through them.
A reasonable default is to start centrally funded to build momentum, then introduce showback (visibility without billing) to establish cost awareness, and finally move to a hybrid chargeback model as the platform stabilizes. Whatever you choose, instrument cloud and inference costs from day one; generative AI in particular can turn into a silent budget leak without FinOps discipline owned by the CoE.
Standing up a CoE is itself a change program, and it should be sequenced. A practical roadmap moves through four phases over roughly 12 to 18 months, with each phase producing tangible proof before the next is funded.
Secure an executive sponsor and write the charter. Choose the initial operating model (usually centralized to start). Stand up a small core team or engage a delivery partner. Inventory the AI work already happening across the organization, including shadow projects. Define the intake and prioritization process. Pick a recognized governance framework to anchor on (NIST AI RMF and ISO/IEC 42001 are common starting points). The deliverable is a signed charter, a named team, and a prioritized backlog.
Deliver two or three high-value, achievable use cases end to end, and build the first slice of shared platform and standards as you do (the reference architecture, deployment pattern, and governance review you will reuse). The objective is proof, not breadth: demonstrable business outcomes plus reusable assets that make the next project faster. Publish the first version of standards and a working template.
Harden the shared platform (model registry, monitoring, evaluation, FinOps), formalize the governance process, and begin embedding AI leads into business units, transitioning toward the hub-and-spoke model. Introduce showback or chargeback. Launch enablement programs and communities of practice. The deliverable is a repeatable production path and a growing pipeline owned partly by the spokes.
Shift more delivery to empowered spoke teams while the hub focuses on standards, platform, governance, and the hardest problems. Mature the funding model to hybrid chargeback. Track and report portfolio-level ROI. Continuously prune standards and process that are not earning their keep. The CoE's success at this stage is measured by how much good AI gets shipped without the hub being in the critical path of every project.
Measure the CoE on business outcomes and delivery velocity, not on activity, headcount, or number of policies written. A focused metric set keeps the CoE honest and gives executives a defensible view of return. Useful KPIs include:
| KPI | What it tells you |
|---|---|
| Use cases shipped to production per quarter | Whether the CoE is converting ideas into value, not just running pilots |
| Realized ROI / value from shipped use cases | Whether AI investment is paying back, in hard or clearly-attributed soft value |
| Time from intake to production | Whether the CoE is accelerating delivery or becoming a queue |
| Reuse rate of shared platforms and components | Whether the shared foundation is actually being adopted |
| Risk incidents averted / model issues caught in review | Whether governance is preventing harm, not just creating paperwork |
| Internal customer satisfaction (NPS from business units) | Whether spokes see the CoE as an enabler or an obstacle |
| AI talent enabled (people trained / certified) | Whether AI fluency is spreading beyond the central team |
Two of these deserve emphasis. Time from intake to production is the single best early-warning signal for the bottleneck failure mode: if it is rising as demand grows, the CoE is becoming a queue. And internal NPS from business units is the clearest leading indicator of whether the CoE is trusted; a CoE with falling internal satisfaction is on its way to being routed around, regardless of how good its standards look on paper.
Most CoEs fail in one of a handful of predictable ways. Knowing the failure modes in advance is the cheapest insurance you can buy.
The throughline across these pitfalls is balance. A CoE has to be central enough to enforce standards and amortize expertise, but not so central that it becomes the bottleneck it was created to remove. Designing explicitly for that balance, through the operating model, charter, and metrics, is the whole game. For a broader catalogue of where enterprise AI programs go wrong, our analysis of enterprise AI adoption in 2026 and the costly mistakes to avoid is a useful companion read.
It helps to ground the framework in concrete examples of what flows through a working CoE. A few representative patterns:
In each case the business outcome is the same shape: faster delivery, lower duplicated cost, consistent governance, and a path to scale that survives staff turnover and regulatory scrutiny.
One of the first practical decisions is how to staff the capability, given that applied-AI and MLOps talent is genuinely scarce and competitive to hire. Three approaches exist, and a blend is usually the most pragmatic.
Building a fully internal CoE maximizes domain knowledge and long-term ownership but is slow, because the specialized roles are the hardest to recruit. Buying through packaged platforms and vendor services moves fast but risks dependence and standards you do not control. Blending keeps strategy, governance, prioritization, and domain context internal while bringing in an external engineering partner for platform build-out and applied delivery, which compresses time-to-value without surrendering control.
The discipline that makes the blend work is simple: the CoE owns the standards and decision rights even when others do some of the building. An external partner should be accelerating your operating model, not becoming it. This is the model many enterprises use to get from charter to first production wins in a single quarter rather than a year, and it is where a specialized Enterprise AI Engineering and Data and AI Transformation partner such as Mind Supernova typically adds the most leverage: supplying MLOps, data engineering, and applied-AI capacity that plugs into a CoE your leaders own.
An AI team typically delivers specific AI projects, while an AI center of excellence is an operating structure that sets standards, builds shared platforms, governs risk, and develops talent across the whole enterprise. A CoE may include delivery teams, but its defining purpose is to make AI delivery repeatable and safe organization-wide, not to ship one set of features.
It depends on enterprise size and operating model. A large enterprise running a federated hub-and-spoke model commonly has a central team of roughly 8 to 15 people plus embedded AI leads in major business units. Smaller organizations can start with a handful of people. The principle is to start lean and grow against demonstrated demand rather than staffing up before there is proven work to justify it.
Most AI CoEs report into the CIO, CTO, or a Chief Data and AI Officer, with an executive steering committee that includes risk, legal, security, finance, and business-unit leaders. What matters more than the exact reporting line is that a senior sponsor stands behind the charter and gives the CoE the authority to enforce standards.
A practical roadmap reaches a working capability with reusable platforms and early production wins in roughly 12 to 18 months, sequenced through foundation, first wins, platform-and-scale, and federation phases. You should expect tangible proof, two or three use cases in production, within the first six months; if there is nothing to show by then, the program is drifting.
Common anchors are the NIST AI Risk Management Framework for structuring risk identification and mitigation, ISO/IEC 42001 for a certifiable AI management system, and the EU AI Act for risk-tiered legal obligations where European markets are in scope. The CoE should map its internal controls to these recognized frameworks rather than inventing bespoke standards, and apply them proportionately to the risk of each use case.
The two dominant failure modes are the ivory-tower CoE, an isolated team whose standards nobody adopts, and the bottleneck CoE, a central team that tries to own everything and slows the organization down. Both stem from getting the operating model and mandate wrong. Other common causes are unclear decision rights, overstaffing too early, weak data foundations, and measuring activity instead of business outcomes.
For most large, multi-business-unit enterprises, the federated hub-and-spoke model is the better long-term choice because it combines central standards and shared infrastructure with business-unit ownership of use cases. Centralized models work well in the early months to establish discipline, and a common pattern is to start centralized and evolve toward federated as platforms and standards mature.
An AI center of excellence is not a status symbol or an org-chart box. It is the operating machine that decides whether your enterprise turns AI ambition into AI that ships, scales, and survives audit. The leaders who get it right treat four decisions as load-bearing: the operating model (usually federated hub-and-spoke for large enterprises), a charter with real decision rights, the five capabilities the CoE owns, and a metric set anchored on production outcomes rather than activity. Get those right and the common pitfalls, the ivory tower and the bottleneck, become avoidable by design rather than discovered the hard way.
If you are designing or resetting your AI operating model, the most valuable next step is usually to draft the charter and pick the operating model before hiring anyone, then sequence the stand-up so that real production wins fund the next phase. Whether you build the capability entirely in-house or bring in an Enterprise AI Engineering partner like Mind Supernova to accelerate the platform and applied delivery while your leaders own the strategy and governance, the goal is the same: a CoE that makes good AI cheaper, safer, and faster to ship everywhere in the business, without ever standing in the way of the people doing the work.
A phased enterprise AI transformation roadmap that takes you from pilot purgatory to enterprise-scale adoption...

An honest enterprise digital transformation playbook for CIOs in 2026: why most stall, the operating model, a...

How to build intelligent enterprise platforms that converge AI, automation, and analytics: the architecture, d...