: A Practical Framework for Enterprise Success")
AI Center of Excellence (AI CoE): A Practical Framework for Enterprise Success
A build-it framework for an AI center of excellence: operating models compared, charter and roles, the capabil...
A phased enterprise AI transformation roadmap that takes you from pilot purgatory to enterprise-scale adoption, with a maturity model, operating model, and ROI sequencing.
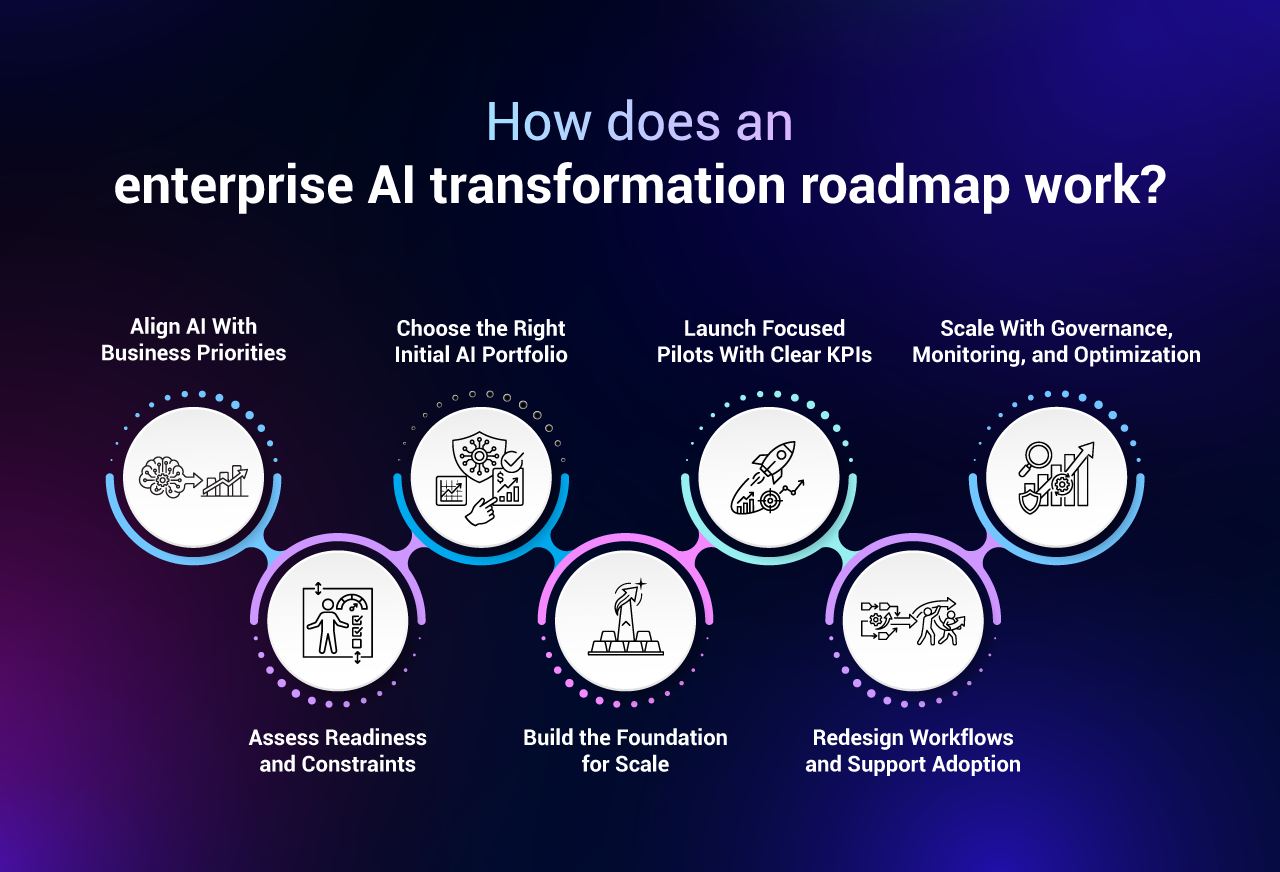
An enterprise AI transformation roadmap is a phased plan that takes an organization from isolated experiments to AI that is embedded in core operations, governed responsibly, and measured against the P&L. It sequences the work into distinct stages—build the data and platform foundation, run disciplined pilots, scale what works, and then embed AI into the operating model—so that each stage produces capabilities the next one can reuse.
The reason this matters has become impossible to ignore. Most enterprises are no longer asking whether to adopt AI; they are trying to understand why the AI they already built never made it out of the lab. McKinsey's 2025 research found that roughly 88% of organizations now use AI in at least one business function, yet only a tiny fraction—around 1%—consider their AI strategies mature. The gap between activity and impact is the single defining problem of enterprise AI in 2026.
This roadmap is written for CTOs, CIOs, and Heads of Innovation who have run their first wave of pilots and now have to answer a harder question from the board: how do we turn this into durable competitive advantage without setting fire to the budget? It is vendor-neutral and practitioner-grade. It covers why pilots stall, an AI maturity model you can self-assess against, the four-phase roadmap itself, the data and platform foundation that makes scaling possible, the operating model and AI Center of Excellence, talent and sourcing decisions, governance, and how to sequence ROI so that early wins fund later bets.
Key Takeaways
Most enterprise AI pilots stall because they are evaluated as science experiments and built as throwaway prototypes, so they have no path to production by design. The demo works, the steering committee applauds, and then the project meets the realities of integration, data quality, security review, monitoring, and unclear ownership—none of which were ever in scope.
Practitioners have given this failure pattern a name: pilot purgatory, or the "POC graveyard," where promising proofs of concept accumulate without ever earning the right to run in production. The numbers behind the name are sobering. RAND Corporation's 2025 analysis estimated that more than 80% of AI projects fail to deliver their intended business value—a meaningful share abandoned before production, others completed but never justifying their cost. MIT Sloan's widely cited 2025 work on generative AI reached a similar conclusion: the large majority of GenAI pilots fail to make it to scaled deployment.
When you decompose the failures, the same root causes appear again and again, and most of them are organizational, not algorithmic:
The lesson is not that pilots are bad. The lesson is that a pilot is only worth running if there is a credible roadmap to production behind it. That roadmap starts with knowing where you actually stand.
An AI maturity model is a staged framework that describes how AI capability deepens across an organization—from ad hoc experiments to AI that reshapes the operating model. Its value is diagnostic: it forces an honest answer to "where are we really?" before you commit capital to "where we want to be."
Most credible models, including Gartner's, describe a similar progression across five stages. The version below blends that structure with the dimensions McKinsey associates with high performers—strategy, talent, operating model, technology, data, and adoption—so you can self-assess on more than just the technology axis.
| Stage | Strategy & sponsorship | Data & platform | Operating model | Typical outcome |
|---|---|---|---|---|
| 1. Foundational | Ad hoc curiosity; no funded strategy | Fragmented, ungoverned data | Individuals experimenting in silos | Demos, no production impact |
| 2. Emerging | Executive interest; first budget | Some pipelines; quality gaps | A central team runs pilots | Promising pilots, pilot purgatory risk |
| 3. Operational | Defined strategy and KPIs | Governed data for key domains | AI owned within select processes | A handful of production use cases |
| 4. Scaled | AI tied to business P&L targets | Shared platform, reusable services | Hub-and-spoke CoE; clear ownership | Measurable ROI across functions |
| 5. Transformational | AI is core to corporate strategy | Real-time, governed, self-serve data | AI embedded in decisions and products | Durable competitive advantage |
The uncomfortable reality for most enterprises is that they self-describe as Scaled or Transformational while operating at Emerging or Operational. Gartner's 2025 research consistently found that data availability and quality remain the top-cited barrier across maturity levels, and that a minority of leaders rate their architecture, workforce, or delivery processes as genuinely AI-ready. If only around 1% of organizations consider their strategy mature, then humility at the assessment stage is not weakness—it is accuracy.
Use the maturity model for two decisions. First, set a realistic 12–18 month target stage rather than aiming for transformation in a single budget cycle. Second, identify which dimension is your binding constraint. For most enterprises it is data and platform, which is why the roadmap below treats foundation as phase one, not a precondition someone else will handle.
An enterprise AI transformation roadmap has four phases—Foundation, Pilots, Scale, and Embed—each of which produces reusable assets that lower the cost and risk of the next. The phases are sequential in emphasis but overlapping in practice: you keep hardening the foundation while you scale, and you keep running new pilots even as mature use cases embed.
| Phase | Primary objective | Key activities | Typical duration | What "done" looks like |
|---|---|---|---|---|
| 1. Foundation | Make the organization buildable | Modern data platform, governance baseline, security and access model, MLOps/LLMOps tooling, executive mandate | 3–6 months (continues after) | Governed data, a reference architecture, and a working deployment path |
| 2. Pilots | Prove value on real problems | Value-to-effort prioritization, 2–4 production-bound pilots, evaluation harnesses, human-in-the-loop design | 3–6 months | At least one pilot in real production with a measured business metric |
| 3. Scale | Industrialize what works | Reusable platform services, the AI Center of Excellence, monitoring at volume, change management, FinOps for AI | 6–12 months | Multiple use cases live across functions with measurable ROI |
| 4. Embed | Make AI part of how the company runs | AI in core processes and products, self-serve enablement, continuous governance, talent flywheel | Ongoing | AI shapes decisions and the operating model, not just point solutions |
The foundation phase exists to make the organization buildable. The goal is not to ship a use case; it is to remove the structural reasons pilots fail later. That means a modern, governed data platform; a security and access model that legal and risk have already blessed; deployment and monitoring tooling (MLOps for traditional models, LLMOps and evaluation harnesses for generative and agentic systems); and an explicit executive mandate that names an accountable owner and a budget.
This is also where you write down a reference architecture so that every future use case starts from a shared baseline instead of reinventing pipelines, secrets management, and observability. Enterprises that skip this phase do not save time; they pay for it repeatedly, once per stalled pilot.
Pilots in this roadmap are different from the experiments that filled the POC graveyard. Each one is selected through a deliberate value-to-effort assessment, tied to a specific business metric, and designed from day one to run in production with human-in-the-loop checkpoints. Run a small number—two to four—rather than a dozen, so the organization can actually finish them. The success criterion for the phase is not "the model works"; it is "at least one pilot is live in production and the business metric moved."
Scaling is where most transformations either compound or collapse, and it is fundamentally an operating-model problem. The work shifts from building one thing well to building a system that lets many teams build well. That means extracting reusable platform services from your early pilots, standing up an AI Center of Excellence to set standards, instrumenting monitoring that holds up at volume, and introducing FinOps discipline so that token and compute costs do not quietly erase your ROI. Change management becomes a first-class workstream here, because adoption—not model accuracy—is now the limiting factor.
In the embed phase, AI stops being a portfolio of projects and becomes part of how the company operates and what it sells. Capabilities are exposed as self-serve services so business units can compose them without a central bottleneck, governance runs continuously rather than as a gate, and a talent flywheel keeps internal capability growing. This is the stage Gartner calls transformational—where AI reshapes decision-making and the operating model itself. Very few enterprises are there yet, which is precisely why getting the earlier phases right is a competitive advantage.
For a broader market view of how these phases are playing out across industries, our analysis of enterprise AI adoption in 2026 covers the trends and the costly mistakes that derail roadmaps in practice.
Enterprise AI requires a governed, accessible, and observable data and platform foundation—because models are only as trustworthy as the data and infrastructure beneath them. The single most-cited barrier to AI maturity, across every survey, is data quality and availability. No amount of model sophistication compensates for a foundation that cannot deliver clean, current, access-controlled data at production volume.
The foundation has a recognizable shape, regardless of which vendors you choose:
A pragmatic rule: build the foundation just ahead of demand, not all at once. You do not need a perfect enterprise data platform before your first pilot, but you do need the slice of it your first pilots depend on, built to a standard the next ten use cases can reuse.
Most enterprises should structure their AI operating model as a hub-and-spoke Center of Excellence: a lean central hub that sets standards, platforms, and governance, with business-unit spokes that build and own use cases on top of them. This model resolves the central tension of scaling—you need consistency and reuse without making a central team the bottleneck for every initiative.
The three common operating models trade off differently:
| Operating model | How it works | Best when | Main risk |
|---|---|---|---|
| Centralized | One team builds and runs all AI | Early maturity; few use cases; scarce talent | Becomes a bottleneck as demand grows |
| Federated / decentralized | Each business unit runs its own AI | High maturity; strong local talent | Duplication, inconsistent governance, no reuse |
| Hub-and-spoke (recommended) | Central hub sets standards and platform; units build on it | Most enterprises scaling past a handful of use cases | Unclear boundaries between hub and spoke responsibilities |
The evidence favors centralized or hybrid coordination. IBM research on Chief AI Officers found that those operating in centralized or hub-and-spoke structures achieved markedly higher ROI than peers in fully decentralized models. The practical trigger for moving to hub-and-spoke is portfolio size: once you have roughly 15–20 active initiatives spread across three or more business units, a single central team can no longer serve everyone without becoming the constraint.
A well-designed CoE owns a specific, deliberately narrow set of responsibilities: reference architecture and shared platform services; standards for evaluation, guardrails, and security; the AI governance framework and review process; reusable components and accelerators; and capability-building so the spokes get better over time. It does not own every use case—that ownership belongs to the business units closest to the value and the risk. We expand this into a full operating blueprint in our AI Center of Excellence framework for enterprises.
The right answer is usually a blend: build durable strategic capability in-house while using specialist partners to move faster on delivery, fill scarce skills, and de-risk the foundation. Treating this as a binary build-versus-buy decision is the wrong frame. The better question is which capabilities are core enough to own and which are better borrowed while you build.
A useful split:
The talent math is unforgiving. Senior AI engineers are scarce and expensive, and the foundation and scale phases need a concentration of skills that few enterprises can hire on the timeline the board expects. This is where an enterprise AI engineering partner earns its place—not as a replacement for your team, but as a force multiplier that gets the platform built, hardens the path to production, and transfers capability as it goes.
This is the work Mind Supernova focuses on. As a Vietnam-based AI engineering company working with enterprise clients across the UK, EU, and US—with async-first delivery and 4+ hours of daily UK overlap—we operate as a Data & AI Transformation and Enterprise AI Engineering partner: building the data and MLOps foundation, engineering production-grade RAG and agentic systems, and helping internal teams move pilots out of purgatory and into production. The goal is always to leave a stronger in-house capability behind, not a dependency.
If you are weighing where to place your bets at the strategy level, our CTO guide to agentic AI strategic investments walks through build-versus-buy, TCO, and risk in more depth.
Enterprises should treat AI governance as a design input from phase one, not a compliance gate bolted on before launch—because retrofitting governance is the surest way to send a working system back to purgatory. Governance done well is an enabler: it gives risk, legal, and security a predictable framework, which is what lets them say yes to production faster.
Anchor your governance to established frameworks rather than inventing your own:
In practice, a scalable governance program includes a model and use-case inventory, a risk-tiered review process so low-risk use cases are not strangled by the same controls as high-risk ones, human oversight designed into high-stakes decisions, monitoring and audit logging in production, and a cross-functional governance body that includes risk, legal, security, and the business. The discipline you build here is also what makes regulators, auditors, and your own board comfortable letting AI touch revenue and customers.
Sequence AI investments so that a small number of high-confidence wins fund the platform and credibility needed for larger, riskier bets—value first, ambition second. The most common ROI mistake is starting with the most transformational use case, which is also the riskiest and slowest, and burning the budget before anything ships. The second most common mistake is the opposite: a scatter of tiny experiments that never accumulate into platform or trust.
A disciplined sequence runs in three waves:
Underpinning all three waves is honest measurement. Tie each use case to a specific business metric before you build, model the total cost of ownership including inference and the human-in-the-loop, and track FinOps for AI so that compute and token costs do not quietly consume the returns. Many technically successful deployments fail their ROI review simply because no one defined the metric up front or accounted for the running cost. For a forward look at where the next wave of returns is emerging, our piece on the AI trends quietly reshaping enterprise growth in 2026 is a useful companion.
Even well-funded transformations repeat a predictable set of mistakes. The ones below account for a large share of failed roadmaps:
For leaders who want to act on this roadmap now, a short list of the decisions that matter most:
An enterprise AI transformation roadmap is a phased plan that moves an organization from isolated AI experiments to AI embedded in core operations. It typically sequences four phases—foundation, pilots, scale, and embed—so that data, platform, operating model, governance, and ROI are addressed in a deliberate order rather than all at once.
They fail mostly for organizational reasons, not technical ones. Pilots are often built as throwaway prototypes on curated data with no deployment path, no monitoring, and no clear owner. When they meet the realities of legacy integration, data quality, security review, and operations, they stall in what practitioners call pilot purgatory. Industry analyses in 2025 put the AI project failure rate near 80%, and most generative AI pilots never scale.
An AI maturity model is a staged framework—commonly five stages from foundational to transformational—that describes how AI capability deepens across strategy, data, operating model, and adoption. Its main use is diagnostic: it gives leaders an honest baseline before they commit budget, and helps them set a realistic next-stage target instead of overstating where they are.
It is a multi-year journey, not a single project. The foundation phase commonly takes three to six months and continues to harden afterward, pilots add another three to six, and scaling typically runs six to twelve months before AI is genuinely embedded. The exact timeline depends heavily on data readiness and executive commitment, which are usually the binding constraints.
An AI Center of Excellence is a central team that sets standards, owns shared platforms and governance, and builds capability across the organization, while business units own their use cases. You need one once your portfolio grows past a handful of use cases—roughly 15 to 20 active initiatives across three or more business units—at which point a fully centralized team becomes a bottleneck and a hub-and-spoke CoE becomes the right structure.
Tie every use case to a specific business metric before building it, and model total cost of ownership including inference, retrieval, and the human-in-the-loop. Sequence investments so quick wins fund reusable platform capability, which in turn funds transformational bets. Many technically successful AI deployments fail their ROI review simply because no metric was defined up front or running costs were underestimated.
For most enterprises, the answer is a blend. Keep strategy, prioritization, proprietary data, and the most sensitive use cases in-house. Use a specialist partner to stand up the data and MLOps platform, engineer production-grade systems under deadline pressure, and fill scarce skills like LLM fine-tuning, enterprise RAG, and agent engineering—ideally one that transfers capability to your team as it delivers.
The defining challenge of enterprise AI is no longer building a model that works in a demo; it is building an organization that can take that model to production, do it again, and keep doing it. The enterprises pulling ahead are not the ones with the most pilots—they are the ones with a deliberate roadmap: an honest read on their maturity, a foundation built before the rush, a small set of production-bound pilots, a hub-and-spoke operating model that scales without bottlenecks, governance designed in from the start, and ROI sequenced so early wins fund later ambition.
None of this requires a perfect plan, but it does require a coherent one. If your organization has pilots that stalled and a board asking why, the most valuable next step is usually a clear-eyed assessment of where you sit on the maturity model and which constraint—data, platform, operating model, or talent—is actually holding you back. From there, the four phases give you a sequence you can fund and defend. And when scarce engineering capacity is the constraint, a partner like Mind Supernova can help stand up the foundation and move stalled pilots into production while your team builds the durable strategy around it. The roadmap is well understood. The advantage goes to the enterprises disciplined enough to follow it.
A build-it framework for an AI center of excellence: operating models compared, charter and roles, the capabil...

An honest enterprise digital transformation playbook for CIOs in 2026: why most stall, the operating model, a...

How to build intelligent enterprise platforms that converge AI, automation, and analytics: the architecture, d...