
Enterprise AI Transformation Roadmap: From Pilot Projects to Enterprise-Scale AI Adoption
A phased enterprise AI transformation roadmap that takes you from pilot purgatory to enterprise-scale adoption...
How to build intelligent enterprise platforms that converge AI, automation, and analytics: the architecture, data foundation, and a roadmap.
An intelligent enterprise platform is a composable system that fuses three capabilities into one operating layer: AI for prediction and reasoning, automation for execution, and analytics for measurement and feedback. The point is not to buy a clever model or a workflow tool. The point is to build a platform where those three feed each other continuously, so a forecast triggers an action, the action generates data, and the data sharpens the next forecast. That loop is what separates an intelligent platform from a pile of disconnected AI features.
Most enterprises in 2026 already own the parts. They have a data warehouse, a few automation flows, and several AI pilots. What they lack is the connective architecture and the operating model that turn those parts into a system. This article is about building that system. It is deliberately distinct from the technology inventory in our companion piece, the enterprise AI stack for 2026: that post explains the components, this one explains how to assemble and run them.
If you are a CIO, CTO, or head of platform engineering trying to move past scattered proof-of-concepts, this is the playbook for the integrated platform and the team model behind it. You can also talk to our engineering team if you want a second opinion on your reference architecture before you commit budget.
Key Takeaways
- An intelligent enterprise platform is defined by the closed loop between AI, automation, and analytics, not by the sophistication of any single component.
- A shared data and AI foundation (governed data products, a feature and context layer, and an event backbone) is the prerequisite. Skip it and you build a fragile demo, not a platform.
- Composability beats a monolithic suite for most enterprises: standardise the foundation and integration contracts, keep the experience layer swappable.
- The operating model matters more than the tooling. A platform team owning golden paths, with federated product squads, is the structure that scales.
- Phase the build over 12 to 18 months. Foundation first, one end-to-end loop second, then horizontal scale. A typical mid-to-large programme runs roughly $1.2M to $4M in year one.
Start with a precise definition, because the term is abused. An intelligent enterprise platform is the shared technology and operating layer that lets business teams build outcomes which sense, decide, and act on enterprise data with minimal bespoke engineering each time. It is a platform in the same sense that an Internal Developer Platform is a platform: reusable foundations and self-service paths, not a one-off application.
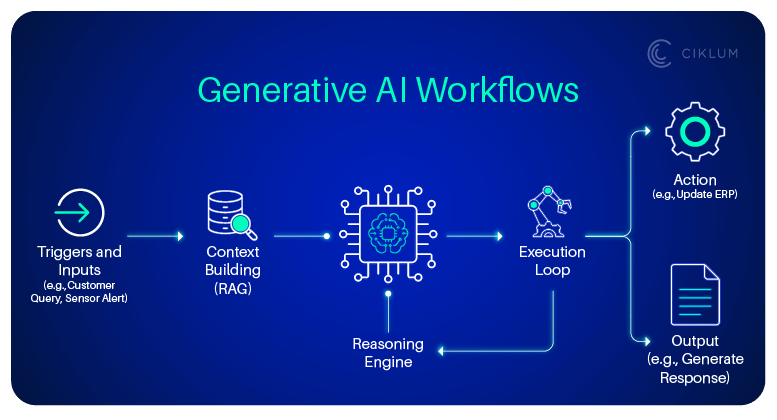
The three capabilities each play a distinct role. Analytics observes and explains what happened and what is likely. AI reasons, predicts, ranks, and increasingly plans. Automation executes the decision in a system of record or a customer channel. None of them is new. The intelligence emerges from binding them into a loop.
Picture a credit-limit decision at a lender. Analytics surfaces a risk signal from transaction patterns. An AI model scores the customer and recommends an adjusted limit. Automation applies the change in the core banking system and notifies the customer. The outcome (default or repayment) flows back as labelled data that retrains the model. Each pass tightens the system. That feedback loop is the asset, and it is why point solutions stall: a chatbot with no path to action and no telemetry never compounds.
The enterprise AI stack describes layers: infrastructure, data, models, orchestration, applications. An intelligent platform is what you get when you wire those layers to automation and analytics and put an operating model around them. The stack is the parts list. The platform is the assembled, running machine plus the team that runs it. Confusing the two is the most common reason transformation budgets evaporate without producing a system anyone can extend.
Almost every failed AI programme fails here. Teams jump to models before they have governed, trustworthy, accessible data. The foundation is unglamorous and non-negotiable. Our deeper treatment of this lives in modern data platforms for AI-driven organizations; the summary below is what the platform layer specifically depends on.
Only about 48% of organisations describe themselves as data-driven, up from roughly 24% a few years earlier [7]. That gap is the foundation gap. The enterprises that close it are the ones whose AI projects survive contact with production.
The platform organises into five horizontal layers plus two cross-cutting concerns. Each layer has a clear contract with the one above and below, which is what makes the whole thing composable rather than a tangle.
+-------------------------------------------------------------+
| EXPERIENCE LAYER |
| Copilots | dashboards | embedded actions | agent UIs |
+-------------------------------------------------------------+
| ORCHESTRATION & DECISION LAYER |
| Workflow engine | agent runtime | business rules | RPA |
| (binds a prediction to an action and an approval) |
+-------------------------------------------------------------+
| INTELLIGENCE LAYER |
| ML models | LLMs + RAG | forecasting | optimisation |
+-------------------------------------------------------------+
| ANALYTICS & SEMANTIC LAYER |
| Metrics layer | BI | feature store | reverse ETL |
+-------------------------------------------------------------+
| DATA FOUNDATION |
| Lakehouse | event backbone (Kafka/CDC) | data products |
+-------------------------------------------------------------+
^ ^
GOVERNANCE & SECURITY OBSERVABILITY & FINOPS
(lineage, access, AI policy) (telemetry, drift, cost)
FEEDBACK LOOP: outcomes from Orchestration flow back
down to Data Foundation and retrain the Intelligence layer
Two design choices carry most of the weight. First, the orchestration layer is where a model output stops being a number and becomes an action with an audit trail and a human approval gate where needed. This is also where agentic workflows live when you adopt them. Second, the feedback path is explicit, not incidental. If outcomes do not flow back to the data foundation, you have automation, not intelligence.
Standardise the bottom three layers and the two cross-cutting concerns. Keep the experience layer and specific orchestration flows swappable per business domain. This gives you reuse where reuse pays (data, governance, model serving) and freedom where business needs diverge (the user-facing experience). It is the same logic as a composable ERP, applied to the intelligence platform.
Vendors sell two stories. One is the integrated suite: buy the SAP, Microsoft, or Salesforce intelligence layer and let it do everything. The other is composable: assemble best-of-breed components on open contracts. Neither is universally right. Use the framework below to decide per capability, not once for the whole enterprise.
Sum the scores. A high differentiation plus high rate-of-change plus capable team points to composable. Low differentiation plus high data gravity plus thin team points to the suite. Most enterprises land on a hybrid: suite for commodity capabilities (HR, finance copilots), composable for the loops that differentiate them.
| Dimension | Composable platform | Monolithic AI suite |
|---|---|---|
| Time to first value | Slower (3 to 6 months) | Faster (weeks for packaged use cases) |
| Differentiation ceiling | High: build what competitors cannot buy | Low: everyone buys the same features |
| Lock-in risk | Lower, if contracts stay open | Higher: data and logic concentrate in one vendor |
| Run cost and complexity | Higher: you own integration and ops | Lower: vendor owns the plumbing |
| Flexibility to swap a model | High | Low to none |
| Best fit | Differentiating loops, capable teams, fast-moving AI | Commodity workflows, thin teams, fast value |
Every intelligent platform programme negotiates the same tensions. Naming them up front prevents the slow, expensive discovery of them in production.
Autonomous agents that act without approval are fast and risky. Human-in-the-loop is safe and slow. The answer is not a single setting. Tier your actions: full autonomy for low-stakes reversible actions (tagging, routing), human approval for high-stakes irreversible ones (refunds above a threshold, account closures). The platform should make this tiering a configuration, not a code change.
A central platform team ensures consistency but becomes a bottleneck. Fully federated squads move fast but produce duplication and drift. The platform-engineering answer applies directly: centralise the foundation and golden paths, federate the building. We explore the org side in our data-driven organization roadmap.
Real-time everything and the largest models are expensive. Most decisions do not need either. Match latency and model size to the decision's value. Reserve real-time streaming and frontier models for the loops where they change outcomes.
Loose governance lets teams ship fast and accumulate shadow AI and compliance debt. Heavy governance kills momentum. The resolution is paved roads: make the governed path the easy path, so teams comply because it is faster, not because they are forced.
| Tension | If you over-rotate one way | If you over-rotate the other | Platform mechanism to balance |
|---|---|---|---|
| Speed vs control | Runaway autonomous actions, incidents | Approval fatigue, no value from AI | Action-risk tiering as config |
| Central vs federated | Platform team bottleneck | Duplication, metric drift | Golden paths + federated squads |
| Cost vs capability | Cloud bill shock, ~27% waste [6] | Underpowered, missed outcomes | FinOps tags + tiered latency/model |
| Innovation vs governance | Shadow AI, compliance debt | Stalled adoption | Paved-road self-service with policy baked in |
Architecture without an operating model is a diagram that rots. By 2026, around 80% of large software organisations are expected to have platform engineering teams, up from 45% in 2022 [4-platform]. The same structure applies to the intelligence platform.
Fund the platform team as a product with a roadmap, not as a project that ends. Fund domain loops against business outcomes with clear value hypotheses. The most common funding mistake is treating the foundation as a one-off capital project; it needs sustained ownership or it decays.
Do not attempt the whole architecture at once. Sequence it so each phase delivers value and de-risks the next. This mirrors the pilot-to-scale pattern in our enterprise digital transformation playbook, applied to the platform specifically.
| Phase | Timeline | Goal | Key deliverables | Success signal |
|---|---|---|---|---|
| 0. Align | Weeks 0 to 6 | Pick one loop and the foundation slice it needs | Value hypothesis, target loop, data audit, governance charter | Funded mandate, named owners |
| 1. Foundation slice | Months 1 to 4 | Build only the data, events, and serving the first loop requires | Two to three data products, event backbone, semantic metrics, model serving | Trusted data flowing, one metric agreed enterprise-wide |
| 2. First closed loop | Months 3 to 7 | Ship one end-to-end loop in production | Model + orchestration + action + feedback telemetry, human approval gate | Loop runs in prod, outcomes retrain the model |
| 3. Golden path | Months 6 to 11 | Turn the bespoke loop into a reusable paved road | Self-service templates, reusable feature/RAG layer, observability, FinOps tags | A second squad ships a loop without platform team writing code |
| 4. Scale and federate | Months 10 to 18 | Multiple loops, federated squads, governance at scale | Model register, drift monitoring, action-risk tiering, cost guardrails | 3+ live loops, governance council operating, costs predictable |
The discipline is in Phase 1: build only the foundation slice your first loop needs. Teams that try to build the complete data platform before shipping anything almost always run out of patience and budget before producing value.
Concrete beats abstract. Consider a pattern used by large retailers and manufacturers (the shape is common across Walmart, Amazon, and Unilever-class operations, even if the internals differ). The goal is intelligent inventory and replenishment.
Analytics aggregates point-of-sale, weather, and supplier-lead-time data into governed data products. AI forecasts demand per SKU per location and flags stockout risk. Automation raises purchase orders within policy limits and escalates exceptions to a planner. The feedback loop captures actual sales versus forecast and supplier performance, which retrains the forecasting model weekly.
Notice what makes it a platform rather than a project. The same forecasting feature store, event backbone, and orchestration runtime are reused for a pricing loop and a logistics-routing loop. The second and third use cases cost a fraction of the first because the foundation already exists. That reuse is the entire economic argument for building a platform instead of three disconnected applications. It is also the AI-ERP convergence we cover in AI-powered ERP and decision intelligence.
Only about 30% of transformation efforts succeed [McKinsey/BCG, industry consensus]. The failures cluster around predictable mistakes. Avoid these and you are ahead of most.
Intelligent platforms have a distinctive cost shape: heavy foundation investment up front, then a long tail of inference and orchestration spend that grows with usage. Budget for both. Treat the numbers below as planning estimates, not quotes; they vary widely by scope and region.
| Cost area | Year 1 estimate (mid-to-large) | Driver | Control lever |
|---|---|---|---|
| Data foundation build | $400K to $1.2M | Data products, lakehouse, event backbone | Build only the slice each loop needs |
| Platform engineering team | $500K to $1.5M | Senior engineers, MLOps, data engineers | Offshore senior engineers; staff augmentation for spikes |
| AI inference and serving | $100K to $600K | LLM tokens, GPU hours, model serving | Tier model size to decision value; cache and route |
| Tooling and licences | $150K to $500K | Orchestration, observability, BI, vendor AI | Avoid tool sprawl; consolidate where contracts allow |
| Governance and security | $100K to $300K | Model register, monitoring, compliance work | Bake into golden paths, do not retrofit |
The single biggest lever on run cost is matching capability to value. Worldwide GenAI spend reached roughly $644B in 2025 [1], and a large share of that is over-provisioned: frontier models answering questions a small model could handle. A FinOps practice with per-loop cost tagging turns this from a surprise into a managed line item. Around 59% of organisations already run FinOps [6]; the intelligent platform makes it mandatory.
Here is the opinionated answer, because the framework above can feel like a non-decision. For most enterprises in 2026: buy the commodity layers, build the loops that differentiate you, and compose the platform that connects them.
Buy infrastructure (cloud, managed lakehouse, managed Kafka), foundation models (do not train your own), observability, and packaged copilots for generic functions like IT support or HR. There is no advantage in reinventing these, and the vendors move faster than you will.
Build the orchestration of your differentiating loops, your feature and context layers, your semantic metrics, and the golden paths your squads use. This is where your competitive advantage lives. It cannot be bought because it encodes your specific business logic and data.
Few enterprises have the senior data, ML, and platform engineers idle and ready. This is where an engineering partner earns its keep on the foundation and golden-path phases, which are heavy on senior engineering but bounded in scope. Teams like Mind Supernova, a Vietnam-based software and AI engineering partner founded in 2023, help enterprises stand up the foundation and first loops with offshore senior engineers working with 4+ hours of daily UK overlap, with engineers able to start in 5 to 7 days. The build-vs-buy nuance for AI specifically is covered in our AI outsourcing partner checklist. The aim is to transfer the platform to your team, not to create a dependency.
The AI stack is the inventory of components (infrastructure, data, models, orchestration). The intelligent platform is the assembled, running system that wires those components to automation and analytics in a feedback loop, plus the operating model that runs it. The stack is parts; the platform is the working machine.
Not everywhere. Reserve real-time streaming for loops where latency changes the outcome, such as fraud or dynamic pricing. Many valuable loops run perfectly well on hourly or daily data. Match data freshness to the decision's value, because real-time everything is expensive and rarely necessary.
Expect the first production loop in roughly three to seven months if you build only the foundation slice it needs. Full platform maturity with multiple federated loops takes 12 to 18 months. Programmes that try to complete the entire foundation before shipping anything usually stall before delivering value.
A central platform team (data engineers, MLOps, platform engineers) owning golden paths, federated domain squads building specific loops, and an AI governance council spanning legal, security, and business. The platform team's product is self-service paved roads, not bespoke builds for every request.
Almost never train foundation models. Buy or access them through APIs and managed services. Your differentiation comes from your data, your retrieval and feature layers, your orchestration, and your governed loops, not from a proprietary base model. Build the parts that encode your business; buy the commoditised intelligence.
The enterprises pulling ahead in 2026 are not the ones with the most AI pilots. They are the ones who built a foundation, shipped one closed loop, turned it into a golden path, and then federated. The intelligence is in the loop and the operating model, not in any single clever model.
This quarter: pick one high-value loop, audit the data it needs, and write the value hypothesis and governance charter. Resist the urge to scope the whole platform. Next 90 days: build only the foundation slice that loop requires, ship it end to end with a human approval gate and outcome telemetry, and prove the feedback loop closes.
If you want senior engineers to help stand up the foundation and first loop without a year-long ramp, schedule a call with our engineering team. We will pressure-test your reference architecture and roadmap before you commit budget.
A phased enterprise AI transformation roadmap that takes you from pilot purgatory to enterprise-scale adoption...
: A Practical Framework for Enterprise Success")
A build-it framework for an AI center of excellence: operating models compared, charter and roles, the capabil...

An honest enterprise digital transformation playbook for CIOs in 2026: why most stall, the operating model, a...