
Multi-Cloud vs Single-Cloud Strategy: What Enterprise CTOs Are Choosing in 2026
Multi-cloud vs single-cloud in 2026: drivers, lock-in, cost, and complexity, with a decision framework and wha...
How to design a CI/CD pipeline that scales across many teams and products: golden templates, security gates, monorepo vs polyrepo, and pitfalls.
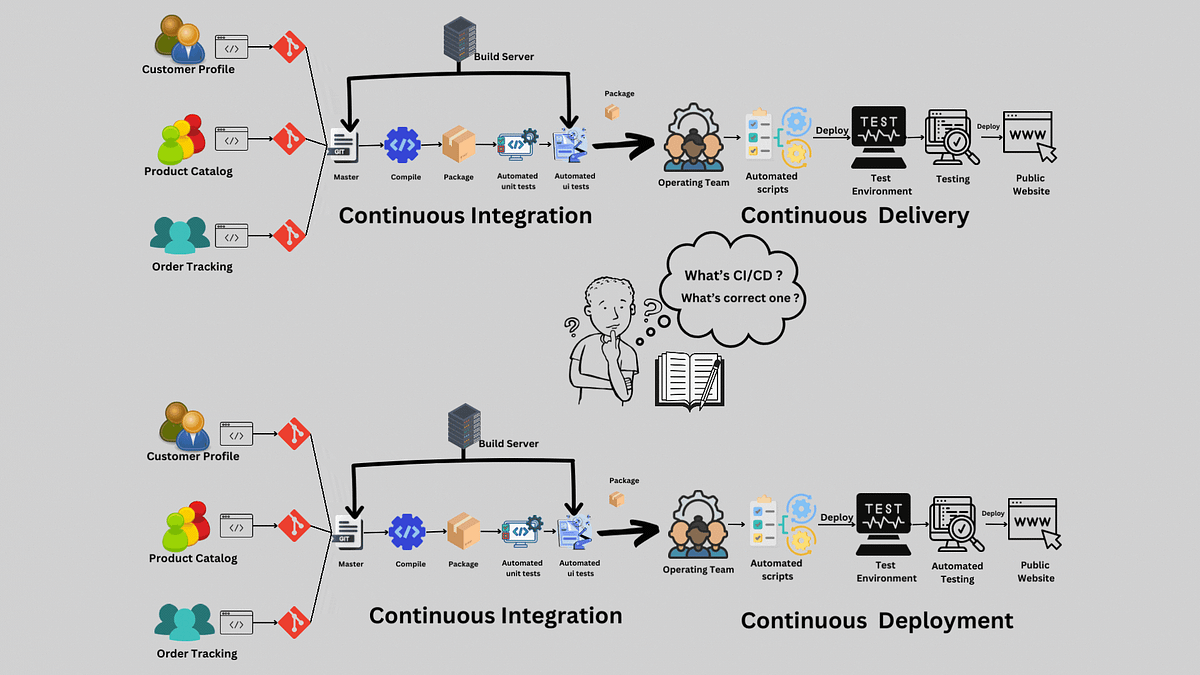
To build a CI/CD pipeline that scales across multiple teams and products, you treat the pipeline itself as an internal product: a small set of standardized, self-service templates that every team consumes, governed by centrally owned security and quality gates, while teams keep ownership of what runs inside their own stages. Scale is not about one giant pipeline; it is about consistent paths, shared guardrails, and low duplication. Get those three right and you can add teams without adding chaos.
This is harder than it sounds. The data shows a strange gap: roughly 83% of organizations practise some form of DevOps, yet continuous integration usage sits near 29% and continuous delivery near 27%, and both have been slipping rather than rising [5]. Most teams have a pipeline. Few have a pipeline that scales. The difference usually comes down to design decisions made early: monorepo versus polyrepo, where security gates live, and who owns the bottlenecks.
This guide is written for CTOs, VPs of Engineering, and Heads of Platform who already run several teams and products and now feel the friction. We cover a decision framework, monorepo versus polyrepo trade-offs, security gate placement, common bottlenecks, a phased roadmap, costs, and a build-versus-buy recommendation. If you want a peer to pressure-test your design, teams like Mind Supernova help enterprises stand up scalable delivery platforms; you can schedule a call when you are ready.
Key Takeaways
- Standardize the pipeline as a product with reusable templates ("golden paths"); let teams own stage internals, but enforce security and quality gates centrally.
- Monorepo simplifies cross-team consistency and atomic changes but demands serious build tooling (affected-only builds, remote caching); polyrepo isolates blast radius but multiplies duplication and version drift.
- Place security gates at four points: pre-commit, pull request, pre-deploy, and runtime. Make blocking gates fast (under 10 minutes) and push slower scans to asynchronous lanes.
- Elite DORA performers deploy 182x more often with an 8x lower change-failure rate and 2,293x faster recovery, yet only 19% of teams reach elite; pipeline design is the lever [4].
- Tool sprawl is a measurable drag on delivery; consolidating runners, caches, and templates usually beats adding another tool [5].
A single team with one product can succeed with an ad hoc pipeline. Copy a YAML file, tweak it, ship. The trouble starts at the second, fifth, and twentieth team. Each copy drifts. Each product picks a slightly different runner, a different secret store, a different test framework. Within a year you have forty pipelines that look similar and behave differently, and nobody can answer a simple question: are we scanning every deployable artifact for vulnerabilities?
Three forces cause the breakage. The first is duplication: copied configuration that nobody refactors. The second is inconsistency: when each team invents its own gates, you cannot prove a baseline to auditors or to yourselves. The third is the shared-resource squeeze: build queues, runner pools, and artifact registries that were sized for three teams now serve thirty.
The fix is organizational as much as technical. You move from "every team writes a pipeline" to "every team consumes a pipeline." This mirrors the platform engineering shift now underway across large enterprises, where central teams provide self-service capabilities rather than tickets. Gartner projects that by 2026, 80% of large software organizations will have platform teams, up from 45% in 2022 [from the platform engineering discussion in our sibling guide]. A scalable CI/CD pipeline is one of the first products such a team should ship.
The most reliable pattern for scale is the "golden path": an opinionated, well-supported default that handles the common case so well that teams choose it over rolling their own. The platform team owns the path. Product teams own their code and their stage logic.
The contract between the two is a template interface. A team includes a versioned template, passes a few parameters (language, deploy target, environments), and inherits the secure default. When the platform team improves the template, every consumer benefits on the next bump. This is how you get consistency without central bottlenecking, and it is the same self-service principle behind an Internal Developer Platform described in our platform engineering versus DevOps guide.
No structural choice affects your pipeline more than repository strategy. It determines how you trigger builds, how you share code, how you isolate failure, and how much tooling you must build before you can scale.
One repository holds many projects. Google, Meta, and (historically) Twitter run enormous monorepos. The appeal is atomic cross-cutting changes: update a shared library and every consumer in one commit, with one review, one CI run. Consistency comes for free because everyone uses the same tooling.
The cost is build engineering. A naive monorepo CI rebuilds and retests everything on every commit, which becomes intolerable past a certain size. You need affected-only builds (Nx, Bazel, Turborepo, Pants) and aggressive remote caching, or your queue times explode. Access control also gets harder when one repository holds many teams' code.
Each service or product has its own repository. Blast radius is naturally contained: a broken build in one repo does not block others. Access control is simple. Teams move independently. This is the path of least resistance for most enterprises.
The cost is drift and duplication. Shared libraries become versioned packages, and you inherit dependency-update sprawl across dozens of repos. A cross-cutting security fix means dozens of pull requests instead of one. Without strong template governance, every repo's pipeline slowly diverges.
| Factor | Monorepo | Polyrepo |
|---|---|---|
| Cross-cutting change | Atomic, one commit/review | Many coordinated PRs |
| Build tooling required | High (affected-graph + remote cache) | Low to moderate |
| Consistency | Strong by default | Requires enforced templates |
| Blast radius of a bad build | Wide without isolation | Naturally contained |
| Access control granularity | Harder (path-based) | Simple (per-repo) |
| Dependency/version drift | Eliminated | Common, needs automation |
| Onboarding new product | Add a directory | Provision a new repo + pipeline |
| Best for | Tight integration, shared platform code | Independent products, strict isolation |
Most enterprises do not need one giant repo or hundreds of tiny ones. A "few-repo" model groups related products into a handful of domain monorepos, each with its own affected-only build graph, while keeping clearly independent products separate. You get monorepo consistency within a domain and polyrepo isolation across domains. Choose your boundaries along team and domain lines, not arbitrary technical ones.
Below is a described reference architecture for a pipeline that serves many teams from shared infrastructure while preserving team autonomy.
Developer push / PR
|
v
[ Trigger layer ] ---- affected-graph detection (monorepo) or per-repo trigger
|
v
[ Reusable template ] <---- owned by platform team, versioned (e.g. v3)
| | |
v v v
Build Test Security gates (pre-commit hooks already ran locally)
| | | SAST, dependency/SCA scan, secret scan, license check
v v v
[ Shared services layer ]
- Autoscaling runner fleet (ephemeral)
- Remote build cache + artifact registry
- Secrets manager (short-lived, OIDC to cloud)
|
v
[ Artifact: signed, SBOM attached ]
|
v
[ Progressive delivery ] ---- staging -> canary -> production
- Pre-deploy policy gate (image signature, SBOM, approvals)
- Runtime gate (health, error budget, automated rollback)
|
v
[ Observability bus ] ---- DORA metrics per team/product, queue time, MTTR
The important detail is the separation of concerns. The trigger and template layers handle consistency. The shared services layer handles efficiency through pooled runners and caching. The delivery and observability layers handle safety and accountability. Each team plugs in without rebuilding any of it.
Security gates are where scaling pipelines most often fail. Teams either bolt every scan onto the critical path, making builds so slow that developers route around them, or they make scans advisory and never enforce a baseline. Neither scales. The answer is to place gates at four distinct points and to keep blocking gates fast.
| Stage | Gate | Blocking? | Target speed |
|---|---|---|---|
| Pre-commit (local) | Secret detection, lint, format | Advisory locally | Seconds |
| Pull request | SAST, SCA/dependency scan, secret scan, unit tests | Blocking | Under 10 min |
| Pre-deploy | Image signing check, SBOM presence, policy-as-code, approvals | Blocking | Under 2 min |
| Runtime | Health checks, error-budget gate, automated rollback | Blocking | Continuous |
| Asynchronous lane | DAST, deep container scan, fuzzing | Non-blocking, ticketed | Hours |
The rule that keeps developers on the golden path: blocking gates must be fast, and slow scans go to an asynchronous lane that files tickets rather than holding the merge. Broken Access Control remains the number one risk in the OWASP Top 10:2021, so access-control tests belong in your blocking PR stage, not in a quarterly review [8]. The economics back this up. IBM put the average cost of a data breach at $4.44M in 2025, down from $4.88M in 2024, with security AI and automation saving roughly $1.9M per breach [9]. Shifting checks left is cheaper than incident response.
One discipline matters above all: short-lived credentials. Replace static cloud keys in your CI with OIDC federation so pipelines mint temporary tokens per run. For deeper coverage of threat modeling and secure SDLC at scale, see our enterprise application security guide.
When a multi-team pipeline slows down, the cause is usually one of a handful of bottlenecks. Diagnose with data: measure queue time, build duration, and flaky-test rate per pipeline before you change anything.
Too few runners for peak demand. Developers wait minutes just to start. Fix with autoscaling ephemeral runners and per-team concurrency limits so one team's mass merge does not starve everyone else.
The single biggest waste in large pipelines is rebuilding unchanged code. Remote caching plus affected-only build graphs can cut build minutes by large margins. In a monorepo this is mandatory, not optional.
Tests that fail randomly destroy trust and trigger needless reruns. Quarantine flaky tests automatically, track them as defects, and never let a flaky suite gate a merge indefinitely. Trust in the pipeline is the asset you are protecting.
The CD Foundation found that excessive tooling correlates with worse delivery, and that CI/CD adoption is slipping even as DevOps spreads [5]. Each extra tool adds integration cost and a new place for config to drift. Consolidate runners, caches, and templates before you adopt the next platform.
Long chains of sequential stages waste wall-clock time. Parallelize independent steps: run linting, unit tests, and SCA scans concurrently rather than in series. Fail fast on the cheapest checks first.
Use the following framework to choose your repository model, governance level, and build-versus-buy posture. Score each axis, then read the recommendation.
| Dimension | Lean toward monorepo / centralized | Lean toward polyrepo / federated |
|---|---|---|
| Shared code volume | High; libraries reused across teams | Low; products are independent |
| Team count | Many teams, one tech culture | Many teams, divergent stacks |
| Compliance/audit needs | Strict; need one provable baseline | Per-product compliance acceptable |
| Build-engineering capacity | You can fund affected-graph tooling | Limited platform engineering capacity |
| Release coupling | Frequent cross-service changes | Services release independently |
| Blast-radius tolerance | Mitigated by tooling | Must isolate failures hard |
Every choice trades one cost for another. Centralization buys consistency and auditability at the price of platform-team investment and a potential single point of contention. Federation buys autonomy and isolation at the price of drift and duplicated effort. There is no free option; there is only the trade you can staff and sustain.
The most expensive mistake is choosing a model your organization cannot support. A monorepo without build engineering becomes a slow, painful bottleneck. A polyrepo without template governance becomes forty divergent pipelines no one can audit. Match the model to the capacity you actually have, not the one you wish you had. When in-house build-platform skills are thin, an engineering partner can stand up the tooling while your team learns it; teams like Mind Supernova bring senior engineers who can start in 5 to 7 days with 4+ hours of daily UK overlap.
Three well-documented patterns show the trade-offs in practice. Google runs one of the largest monorepos in existence, made viable only by heavy investment in build tooling (Bazel originated there) and remote caching. The lesson is not "use a monorepo"; it is "a monorepo without that tooling investment does not scale." Most enterprises lack Google's build-engineering budget, which is precisely why the few-repo middle ground exists.
Spotify popularized autonomous squads with strong polyrepo ownership, then invested in an internal developer platform (Backstage, later open-sourced) to claw back consistency that pure autonomy had cost them. The arc is instructive: full federation produced drift, so they added a golden-path layer on top. That layer is exactly the template-and-portal pattern recommended here.
Amazon Prime Video's 2023 case is a useful counterweight to architectural fashion. One team moved a monitoring service from a distributed serverless and microservices design back to a more consolidated approach and reported over 90% cost reduction. The pipeline lesson is that more services and more pipelines are not automatically better; consolidation, when it fits the workload, can dramatically cut both cost and operational overhead. Design your pipeline topology to match how your software is actually structured, a theme we explore in our web application architecture guide.
You do not migrate every team at once. You build the platform, prove it on willing teams, then expand. Treat the rollout like a product launch with users to win over.
| Phase | Timeline | Focus | Success signal |
|---|---|---|---|
| 1. Baseline | Weeks 1–4 | Measure DORA metrics, queue time, gate coverage per team | You can see current state with data |
| 2. Golden path v1 | Weeks 5–10 | Build reusable templates, shared runners, mandatory gates | Two pilot teams ship via the template |
| 3. Security baseline | Weeks 8–14 | SAST/SCA/secret scan, signing, SBOM, OIDC credentials | Every pilot artifact is signed and scanned |
| 4. Caching and scale | Weeks 12–18 | Remote cache, affected-only builds, autoscaling runners | Build minutes and queue time drop materially |
| 5. Org rollout | Weeks 16–28 | Migrate teams, deprecate bespoke pipelines, portal/self-service | 80%+ of teams on the golden path |
| 6. Continuous improvement | Ongoing | Template versioning, flaky-test program, DORA dashboards | Metrics trend toward elite over quarters |
Note the overlapping timelines: security and caching work can begin before the full rollout. Resist a big-bang migration. The DORA 2024 research is blunt about the prize: elite performers deploy 182x more often, have 127x faster lead time, an 8x lower change-failure rate, and recover 2,293x faster than low performers, yet only 19% of teams reach elite [4]. Steady, measured improvement is how you climb. To benchmark where you start, our DevOps maturity model guide gives you a five-level assessment.
A 2024 finding deserves attention before you assume AI coding tools will fix your pipeline. DORA reported that while roughly 76% of developers use AI daily, each 25% increase in AI adoption correlated with about a 1.5% drop in delivery throughput and a 7.2% drop in stability [4]. Faster code generation can flood a weak pipeline with more changes than its gates and review capacity can safely absorb.
The implication is direct: AI raises the volume of changes, so your pipeline's gates, tests, and rollback capability must be strong enough to handle that volume safely. A scalable pipeline is the prerequisite for getting value from AI-assisted development, not an afterthought. For how AI is reshaping the whole delivery lifecycle, see our companion piece on AI and the SDLC.
Pipeline costs hide in three buckets: compute, tooling licences, and the engineering time to build and run the platform. The largest hidden cost is wasted build minutes from cache misses and full rebuilds, which scales linearly with team count if you ignore it.
| Cost driver | Typical pattern | Optimization lever |
|---|---|---|
| CI compute / runner minutes | Scales with team count and rebuild waste | Remote cache, affected-only builds, ephemeral autoscaling |
| Platform licences | Per-seat or per-minute; grows with adoption | Consolidate tools; avoid sprawl |
| Platform team headcount | 2–5 engineers for a mid-size org (estimate) | Reusable templates reduce per-team support load |
| Security tooling (SAST/SCA/DAST) | Often bundled or per-repo | Centralize scans in shared templates |
| Incident and rework cost | Rises sharply with weak gates | Strong gates; breach savings up to ~$1.9M [9] |
The honest framing: a platform team is a real fixed cost, justified only when it removes more duplicated effort across product teams than it consumes. Below roughly five to eight teams, a lighter shared-template approach without a dedicated platform team often makes more sense. Above that, the duplication you eliminate usually pays for the team several times over.
You will not build a CI/CD engine from scratch; that decision was made for you years ago by GitHub Actions, GitLab CI, and similar platforms. The real build-versus-buy question is about the layer on top: the golden-path templates, the developer portal, and the policy gates.
Use a managed CI/CD platform for the execution engine, and adopt open frameworks for the layers above: an open developer portal (such as Backstage) rather than a bespoke one, off-the-shelf SAST/SCA scanners, and standard policy-as-code engines. Buying the commodity layers frees your engineers to build what is actually differentiating.
Your reusable templates, your golden paths, and your team-specific deployment logic are yours to build, because they encode how your organization actually ships. This is thin, high-leverage glue, not a product. Keep it small and versioned.
Buy or adopt the engine and the commodity scanners. Build only the templates and policies that encode your standards. If you lack the platform engineering depth to build that glue well, bring in senior engineers to do it with you rather than buying a heavyweight all-in-one tool that locks you in. An offshore engineering partner with strong DevOps depth, such as Mind Supernova, can stand up the platform and transfer ownership to your team. You can find that team via staff augmentation or a dedicated team model, and read more about disciplined delivery in our existing guide on building an offshore engineering center.
Choose based on shared-code volume and your build-engineering capacity. Use a monorepo only if you can fund affected-only build tooling and remote caching. Otherwise prefer a few-repo model that groups related products into a handful of domain monorepos, balancing consistency with failure isolation across domains.
Place gates at four points: pre-commit, pull request, pre-deploy, and runtime. Keep blocking gates fast (under 10 minutes) by running SAST, SCA, and secret scans on pull requests, and move slower scans like DAST and fuzzing to asynchronous, non-blocking lanes that file tickets.
Wasted build minutes from full rebuilds and cache misses, closely followed by runner queue starvation and flaky tests. Remote caching with affected-only builds and autoscaling ephemeral runners clears most of it. Measure queue time and build duration per pipeline before optimizing anything.
Usually above five to eight teams. A platform team is a fixed cost justified when it removes more duplicated effort than it consumes. Below that threshold, shared reusable templates without a dedicated team often suffice. Above it, the duplication eliminated typically pays for the team many times over.
Not on their own. DORA 2024 found that higher AI adoption correlated with small drops in throughput and stability, because AI raises change volume faster than weak pipelines can absorb it safely [4]. A scalable pipeline with strong gates and rollback is the prerequisite for capturing AI's benefits.
A CI/CD pipeline that scales is a product, not a script. Standardize the path with versioned templates, centralize security and quality gates, pool your runners and caches, and let teams own what runs inside their stages. Choose a repository model your organization can actually staff, and measure everything with DORA metrics so improvement is visible rather than felt.
This quarter: instrument your current pipelines, capture DORA metrics and gate coverage per team, and ship a golden-path template to two pilot teams. Next 90 days: add the security baseline (signing, SBOM, OIDC), turn on remote caching and affected-only builds, then begin migrating teams and deprecating bespoke pipelines.
If you want senior engineers to design and stand up this platform alongside your team, with 4+ hours of daily UK overlap and engineers who can start in 5 to 7 days, talk to our engineering team. You can also explore how we work through software outsourcing and a dedicated team model.
Multi-cloud vs single-cloud in 2026: drivers, lock-in, cost, and complexity, with a decision framework and wha...

Platform engineering vs DevOps: what internal developer platforms are, when to build a platform team, and the...

A practical DevOps maturity model and DORA metrics to assess where your engineering org stands today, plus a r...