
How to Build a CI/CD Pipeline That Scales Across Multiple Teams and Products
How to design a CI/CD pipeline that scales across many teams and products: golden templates, security gates, m...
Platform engineering vs DevOps: what internal developer platforms are, when to build a platform team, and the org model that makes them work.
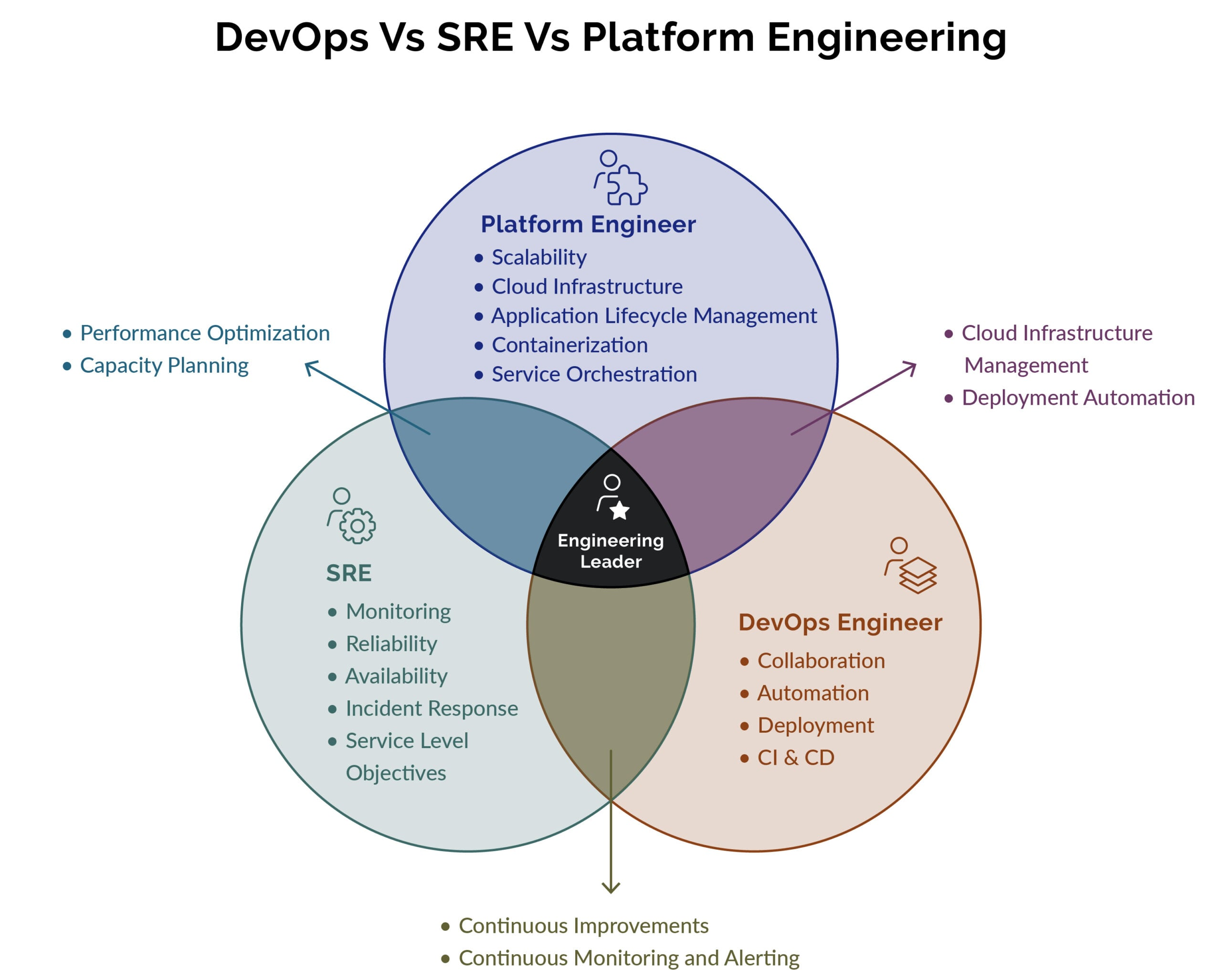
Platform engineering and DevOps are not competitors. Platform engineering is the next operational stage of DevOps: instead of asking every team to assemble its own pipelines, infrastructure, and guardrails, a dedicated platform team builds an internal developer platform (IDP) that turns those capabilities into self-service "golden paths". The shift matters because the DevOps promise of "you build it, you run it" quietly pushed enormous cognitive load onto product engineers, and platform engineering is the structural fix.
If you lead engineering at a large organisation, this is no longer fringe. Gartner projects that by 2026, 80% of large software engineering organisations will have established platform teams, up from 45% in 2022 [1]. That is one of the fastest operating-model shifts the industry has seen since DevOps itself. The question for most technology leaders is not whether to invest in platform engineering, but when to start, how to staff it, and how to avoid building an expensive internal product that nobody wants to use.
This article gives you a decision framework for when to build a platform team, the organisational model that works, a phased roadmap, real cost ranges, the most common failure modes, and a build-versus-buy recommendation grounded in current data.
Key Takeaways
- Platform engineering is not a replacement for DevOps. It productises DevOps capabilities into a self-service internal developer platform with golden paths, so product teams move faster with less cognitive load.
- Gartner projects 80% of large software organisations will have platform teams by 2026, up from 45% in 2022 [1]. This is a mainstream operating-model shift, not an experiment.
- The strongest signal that you need a platform team is duplication: when five squads have each rebuilt the same CI/CD, observability, and environment setup, central investment pays for itself.
- Treat the platform as a product, not a project. Give it a product manager, optional adoption, and measurable outcomes tied to DORA metrics rather than mandated usage.
- Most organisations under roughly 30 to 50 engineers do not need a dedicated platform team yet. Below that scale, a well-factored shared toolchain usually wins on cost.
DevOps was a cultural and technical movement to collapse the wall between development and operations. It gave us continuous integration, infrastructure as code, automated deployment, and the principle that the team writing the code also operates it. For high-performing teams the payoff is dramatic. DORA's 2024 research found elite performers deploy 182 times more often, recover from incidents 2,293 times faster, and have an 8 times lower change-failure rate than low performers [2].
So why introduce a new discipline? Because the "you build it, you run it" model has a hidden tax. As tool ecosystems grew, each product team became responsible for Kubernetes manifests, pipeline configuration, secret management, observability wiring, security scanning, and cloud provisioning. That is a lot of undifferentiated work for engineers whose job is to ship product features. The result is cognitive overload, inconsistent practices across squads, and the same problems solved five different ways.
DevOps is a philosophy and a set of practices. Platform engineering is the discipline of building an internal product that delivers those practices as a reliable, self-service capability. One is the goal; the other is an operating model for reaching it at scale.
| Dimension | Traditional DevOps | Platform engineering |
|---|---|---|
| Primary unit | Cross-functional product team owning its own ops | Central platform team serving many product teams |
| What it produces | Practices, culture, shared scripts | An internal developer platform (a product) |
| Developer experience | Each team assembles its own toolchain | Golden paths and self-service templates |
| Cognitive load | High and spread across all teams | Concentrated in the platform team by design |
| Consistency | Varies team to team | Standardised defaults, paved roads |
| Success metric | Deployment frequency, lead time per team | Adoption, time-to-first-deploy, fleet-wide DORA |
| Failure mode | Tool sprawl, duplicated effort | An unused platform nobody asked for |
Note the last row. DevOps fails through fragmentation. Platform engineering fails through building something teams route around. Both failure modes are expensive, and the rest of this article is largely about avoiding the second one.
An internal developer platform is the curated layer of self-service tooling, automation, and guardrails that sits between your engineers and the underlying infrastructure. It is not a single product you buy. It is a composition of capabilities, presented through a consistent interface, so a developer can provision an environment, scaffold a service, ship to production, and observe it without filing tickets or learning the internals of your cloud.
A useful IDP typically exposes five capability groups.
The central design idea is the golden path: the recommended, well-supported, opinionated way to build and run a service. A team that follows the golden path gets speed, automated compliance, and support. The golden path must be the path of least resistance, not a mandate enforced by policy.
Crucially, a good platform lets teams step off the path when they have a real reason. Make the default easy and the exception possible. The moment the platform becomes a golden cage that blocks legitimate work, teams build shadow tooling and your investment erodes.
Building a platform team too early is one of the most common and costly mistakes in this space. You divert senior engineers to serve an internal audience that is too small to justify the overhead. Building too late is also costly: by then every squad has its own snowflake setup, and consolidation becomes a migration project.
Use the readiness signals below. Score each from 0 (not true) to 2 (strongly true). A total of 10 or higher is a strong signal to invest. Between 6 and 9, run a lightweight pilot. Below 6, improve your shared toolchain first.
| Readiness signal | What to look for | Score 0 to 2 |
|---|---|---|
| Team count | Roughly 5 or more autonomous product teams | 0 / 1 / 2 |
| Engineering headcount | Above roughly 30 to 50 engineers | 0 / 1 / 2 |
| Duplication | Multiple teams have rebuilt the same CI/CD, observability, or provisioning | 0 / 1 / 2 |
| Onboarding friction | New service or new hire takes weeks to reach production | 0 / 1 / 2 |
| Inconsistency cost | Incidents and audits suffer from non-standard setups | 0 / 1 / 2 |
| Cognitive overload | Product engineers spend significant time on undifferentiated ops | 0 / 1 / 2 |
| Executive sponsorship | A leader will fund a multi-quarter internal product | 0 / 1 / 2 |
If duplication is your dominant pain and you have enough teams to amortise central investment, build a platform team. If your main pain is process or culture, fix that first. A platform will not rescue an organisation that has not yet adopted basic DevOps practices. It accelerates teams that already deploy; it does not teach teams that do not.
Below roughly 30 engineers, a shared internal toolchain owned part-time by a few senior engineers usually beats a dedicated team on cost and focus. The economics only flip once the audience is large enough that one platform investment serves many consumers. For organisations scaling fast, our team at Mind Supernova often sees the inflection point arrive somewhere between the fourth and sixth product team, which is also where onboarding friction starts to dominate roadmaps.
The most widely adopted mental model for structuring platform engineering comes from Team Topologies. It defines four team types, and platform engineering maps cleanly onto two of them.
The single most important organisational decision is to treat the platform as a product with real product management, not as an internal IT project. That means a platform product manager, a roadmap driven by user research with your own engineers, and a commitment to optional adoption. If teams must use the platform by mandate, you lose the feedback loop that keeps it good.
| Role | Responsibility | Typical ratio |
|---|---|---|
| Platform product manager | Roadmap, user research, prioritisation, adoption | 1 per platform team |
| Platform engineers | Build and run IDP capabilities and golden paths | 4 to 8 to start |
| Site reliability / ops | Reliability of the platform itself | 1 to 2 |
| Developer experience lead | Documentation, onboarding, internal advocacy | 1 |
| Security partner | Embeds guardrails into golden paths | Shared / embedded |
A common starting size for a large organisation's first platform team is six to eight people. Keep it small enough to ship and accountable to adoption metrics from day one. Resist the urge to absorb every ops function into the platform team on launch; scope creep here is how a focused product becomes a slow internal bureaucracy.
An internal developer platform is best understood as layers. The infrastructure sits at the bottom, the platform abstracts and automates it in the middle, and developers interact through self-service interfaces at the top. The diagram below shows a reference shape.
DEVELOPERS (stream-aligned product teams)
| self-service, golden paths
+---------------------------------------------+
| DEVELOPER INTERFACE |
| portal | CLI | templates | pipelines |
+---------------------------------------------+
| PLATFORM CAPABILITIES |
| scaffolding | provisioning | delivery | |
| observability | secrets | security gates |
+---------------------------------------------+
| ORCHESTRATION & POLICY |
| Kubernetes | IaC | policy-as-code |
+---------------------------------------------+
| INFRASTRUCTURE (cloud, networking, data) |
+---------------------------------------------+
Three architectural choices shape every IDP. Work through them in order.
| Trade-off | Lean toward standardisation when | Lean toward flexibility when |
|---|---|---|
| Golden path strictness | Compliance and consistency dominate | Teams have diverse, legitimate needs |
| Abstraction depth | Most consumers are not infrastructure experts | Consumers are senior and want control |
| Portal vs config | You want discoverability and broad reach | You want everything in Git and reviewable |
| Centralisation | Duplication and audit risk are high | Innovation speed matters more than uniformity |
The recurring tension is autonomy versus standardisation. Platform engineering exists to give teams more autonomy over outcomes by removing the toil, not to centralise control over how they work. Keep that framing and most architectural arguments resolve themselves. Architecture choices here connect directly to your wider stance on monolith versus microservices, covered in our companion piece on web application architecture in 2026.
The most instructive public example is Spotify. As the company grew to hundreds of engineering squads, the cost of every team managing its own tooling, services, and documentation became unsustainable. Spotify built an internal developer portal to give engineers a single place to create services from templates, find ownership and documentation, and navigate the software catalogue. In 2020 it open-sourced that portal as Backstage, which later became a Cloud Native Computing Foundation project.
The lesson is not "adopt Backstage". It is the pattern Spotify followed: treat developer experience as a product, centralise the catalogue and golden paths, and let teams stay autonomous on top of a shared foundation. Many organisations now use Backstage as the portal layer of their IDP, while others build the same capability with different tools. The portal is the visible tip; the golden paths underneath are what create the value.
A second pattern worth naming is the cost discipline that platform thinking enables. When delivery is standardised, you can reason about your fleet as one system rather than dozens of bespoke setups, which makes architectural course corrections feasible. That same fleet-level thinking is why elite DevOps performers in DORA's data sustain such large leads on recovery and change-failure rate [2]: consistency compounds.
Treat the rollout as a product launch, not an infrastructure migration. The phases below assume a large organisation that already has functioning DevOps practices in individual teams.
Do not start by building a portal. Start by interviewing your engineers. Find the single most painful, most duplicated workflow, often new-service creation or environment provisioning. Build one golden path for it end to end, with one or two friendly pilot teams. Measure time-to-first-deploy before and after.
Harden the first golden path, add observability and security defaults, and onboard a few more teams by invitation. Publish a lightweight service catalogue. Track adoption weekly. The goal is voluntary pull from teams who hear the pilot saved real time.
Introduce a portal as the entry point, formalise the platform product manager role, and establish a public roadmap. Wire fleet-wide DORA metrics so you can show organisation-level improvement. Standardise the second and third golden paths.
Open contribution so stream-aligned teams can extend the platform. Run regular developer-experience surveys. Retire shadow tooling as golden paths absorb its use cases. At this point the platform should reduce, not add to, total engineering cost.
| Phase | Focus | Primary metric | Risk to watch |
|---|---|---|---|
| 1 | One golden path, pilot teams | Time-to-first-deploy | Building tools nobody asked for |
| 2 | Expand paths, prove value | Voluntary adoption | Mandating usage too early |
| 3 | Portal, product management | Fleet-wide DORA | Scope creep, feature bloat |
| 4 | Scale and self-sustain | Developer satisfaction | Platform team becoming a bottleneck |
Most failed platform programmes fail for organisational reasons, not technical ones. These are the patterns to avoid.
For organisations assessing how ready they are before investing, a structured baseline helps. Our companion guide on the DevOps maturity model gives you the assessment lens to know whether platform engineering is your next step or a premature one.
The headline cost of a platform team is salaries: typically six to eight engineers plus a product manager in the first year. But the real cost decision is opportunity cost, because those are usually senior people you could otherwise put on revenue features. The justification has to be that they unlock many more engineers downstream.
The break-even logic is straightforward. If a platform team of seven saves each of 70 product engineers even a few hours a week of undifferentiated toil, the leverage is large. Below a certain audience size, that arithmetic does not work, which is why scale is the gating factor in the decision framework above.
| Cost area | Notes | Relative weight |
|---|---|---|
| Platform team salaries | 6 to 8 engineers plus PM, ongoing | Highest |
| Tooling and licences | Portal, IaC, observability, scanning | Medium |
| Cloud and infrastructure | Platform-run environments and control plane | Medium |
| Migration and onboarding | Moving teams onto golden paths | Medium, front-loaded |
| Opportunity cost | Senior engineers off feature work | High, often underestimated |
Treat figures as planning estimates. Tool sprawl is a real hidden cost: the CD Foundation's 2024 research found that despite roughly 83% of organisations practising DevOps, continuous integration usage sat near 29% and continuous delivery near 27%, partly because fragmented tooling slows delivery [3]. A platform that consolidates that sprawl can pay for itself, but only if adoption is real.
You have three broad routes to an internal developer platform, and most large organisations end up with a blend.
| Approach | Best for | Trade-off |
|---|---|---|
| Build from open source | Large orgs with strong platform talent and specific needs | Maximum fit and control, highest ongoing maintenance |
| Adopt a framework (e.g. Backstage) | Orgs wanting a portal foundation they will extend | Faster start, still needs engineering to operate |
| Buy a managed IDP | Teams that want self-service fast, fewer maintainers | Quickest value, less control, vendor dependency |
Buy or adopt for commodity layers, build only where you have genuine differentiation. The portal, the catalogue, and standard pipelines are largely solved problems; reinventing them rarely creates advantage. Where your organisation has unusual compliance, scale, or domain constraints, build those golden paths yourself. The goal is to spend your scarce platform engineering talent on what is specific to you, not on rebuilding generic plumbing.
If you lack the senior platform talent to start, an external engineering partner can stand up the first golden paths and transfer ownership to your team. Teams like Mind Supernova help enterprises bootstrap platform capabilities with senior engineers who can start in five to seven days and work async-first with 4+ hours of daily UK overlap, which suits a build-then-handover model. You can talk to our engineering team via our contact page if that fits where you are. For organisations also weighing where their platform work should sit, our perspective on building an offshore engineering center covers the operating-model questions in depth, and broader platform thinking connects to the enterprise technology stack for 2026. The same self-service principles also underpin CI/CD pipelines that scale across many teams, which is usually the first golden path a platform team ships.
No. Platform engineering is the next operational stage of DevOps, not a replacement. DevOps defines the practices and culture; platform engineering productises those practices into a self-service internal developer platform so product teams can move faster with less cognitive load. You still need DevOps principles underneath.
As a rough guide, dedicated platform teams start paying off above roughly 30 to 50 engineers and around five autonomous product teams. Below that, a shared toolchain owned part-time usually wins on cost. The real trigger is duplication: when teams keep rebuilding the same tooling, central investment is justified.
A golden path is the recommended, well-supported, opinionated way to build and run a service on your platform. It bakes in CI/CD, observability, and security defaults so following it is the path of least resistance. Good golden paths are easy to follow but allow controlled exceptions when teams have real reasons.
Buy or adopt commodity layers like the portal and standard pipelines, and build only where you have genuine differentiation such as unusual compliance or scale needs. Most large organisations blend approaches. Reserve scarce platform talent for what is specific to your business rather than rebuilding generic infrastructure.
Track voluntary adoption, time-to-first-deploy for new services, and fleet-wide DORA metrics: deployment frequency, lead time, change-failure rate, and recovery time [2]. Add a regular developer-experience survey. Avoid measuring mandated usage, because forced adoption hides whether the platform is actually good.
Platform engineering wins when it earns adoption, not when it is mandated. The discipline exists to give product teams more autonomy over outcomes by removing the toil that DevOps inadvertently pushed onto them. With Gartner projecting 80% of large software organisations to run platform teams by 2026 [1], the operating-model shift is already underway, but the failure modes are organisational, not technical.
This quarter: interview your engineers, score yourself against the readiness framework, and identify the single most duplicated workflow you could turn into a golden path. Next 90 days: stand up that one path with two pilot teams, measure time-to-first-deploy, and decide whether voluntary pull justifies a dedicated team.
If you want senior engineers to help bootstrap your first golden paths and hand them over to your team, schedule a call with our engineering team. Start small, treat the platform as a product, and let adoption tell you the truth.
How to design a CI/CD pipeline that scales across many teams and products: golden templates, security gates, m...

Cloud-native application development explained: containers, Kubernetes, and serverless, when each fits, and ho...

Multi-cloud vs single-cloud in 2026: drivers, lock-in, cost, and complexity, with a decision framework and wha...