
AI-Powered ERP: Moving Beyond Process Automation to Decision Intelligence
AI-powered ERP moves beyond automation to decision intelligence: agents in ERP, the data foundation required,...
Monolith, microservices, or modular monolith in 2026? A decision framework, trade-offs, and real cases to choose the right web app architecture.
For most teams in 2026, the right web application architecture is a well-factored modular monolith, not a fleet of microservices. That sentence will annoy a lot of people who spent the last decade splitting systems into dozens of services, but the evidence has shifted. ThoughtWorks now lists microservices as a technique to "Trial" rather than adopt by default, and the most quoted real-world story of the period is Amazon Prime Video moving a workload off serverless microservices and back into a monolith for a cost reduction of more than 90 percent.
This guide is a decision framework for senior technology buyers choosing between a monolith, microservices, and the modular monolith middle ground. It covers the trade-offs, a phased roadmap, the costs nobody budgets for, the mistakes that quietly sink projects, and a clear build-versus-buy recommendation. The goal is a defensible architecture choice you can put in front of a board, not a fashion statement.
Architecture is an organizational decision as much as a technical one. The shape of your system tends to mirror the shape of your teams, so the question is never purely "which pattern is best" but "which pattern fits the team, the domain, and the money we actually have." We will keep that lens throughout.
Key Takeaways
- Start with a modular monolith. MonolithFirst (Martin Fowler) holds up: build a clean, well-bounded monolith and extract services only when concrete scale or team pressure justifies it.
- Microservices solve organizational scaling, not performance. They add network latency, operational cost, and distributed-system complexity that small and mid-size teams rarely recover from.
- Amazon Prime Video publicly moved a monitoring service from serverless microservices back to a monolith and cut cost by over 90 percent (2023). Size the pattern to the workload.
- The distributed monolith is the worst outcome: microservices coupling without microservices independence. Avoid it by enforcing module boundaries before you split deployment units.
- Buy your platform plumbing (cloud, orchestration, observability, IDP tooling) and build your domain logic. Spend engineering budget where it differentiates you.
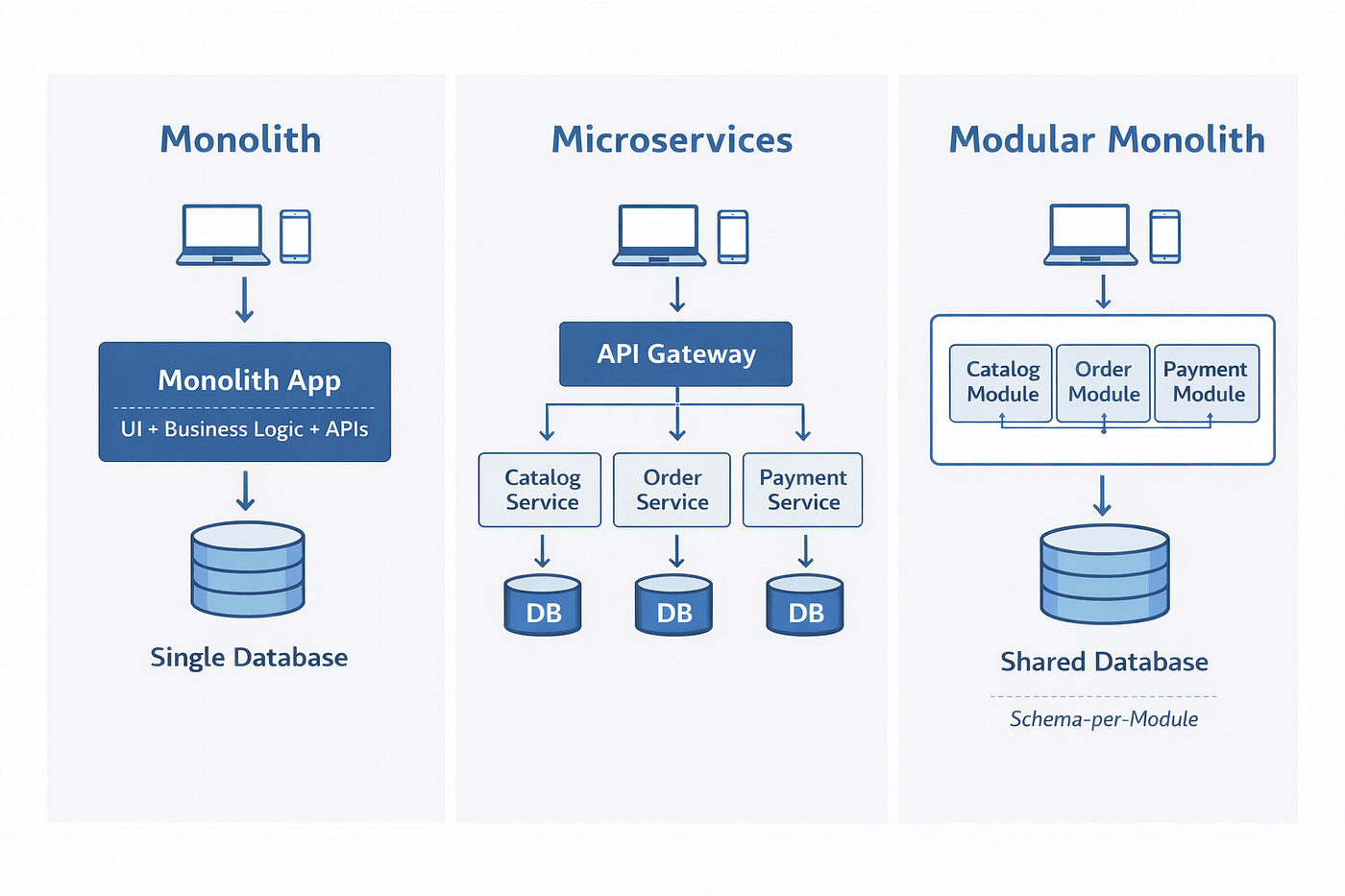
Confusion starts with loose definitions, so let us pin them down. A monolith is a single deployable unit: one codebase, one build, one process boundary, usually one primary database. It can still be internally clean or internally a mess. The deployment topology says nothing about code quality.
A modular monolith is a single deployable unit with strictly enforced internal module boundaries. Each module owns its data and exposes a narrow interface to the others. You get the operational simplicity of one deploy with much of the architectural discipline people expect from services. It is the pragmatic middle ground and, for most teams, the correct starting point.
A microservices architecture splits the system into many independently deployable services, each owning its data and communicating over the network. The promise is independent scaling and independent team velocity. The price is distributed-system complexity: network failure, eventual consistency, distributed tracing, and a far larger operations bill.
The single most useful framing: a monolith and a modular monolith differ in discipline, while a modular monolith and microservices differ in deployment. Moving from messy monolith to modular monolith is a refactoring exercise inside one process. Moving from modular monolith to microservices is crossing a network boundary, and that crossing is where most of the cost, risk, and regret lives. Treat the network as a one-way door you open only when you must.
The table below compares the three patterns across the dimensions that actually drive a 2026 decision. Read it as relative, not absolute: a disciplined team can make any of these work, and an undisciplined team can ruin all three.
| Dimension | Monolith | Modular monolith | Microservices |
|---|---|---|---|
| Deployable units | One | One | Many |
| Internal boundaries | Often weak | Strictly enforced | Enforced by network |
| Initial delivery speed | Fastest | Fast | Slowest |
| Operational complexity | Low | Low | High |
| Independent scaling | No | Limited | Yes |
| Team autonomy at scale | Low | Medium | High |
| Failure isolation | Weak | Moderate | Strong (if done right) |
| Latency overhead | None (in-process) | None (in-process) | Network on every hop |
| Infrastructure cost | Lowest | Low | Highest |
| Debugging difficulty | Low | Low to medium | High (distributed tracing) |
| Best team size | 1 to 8 engineers | 5 to 40 engineers | 40+ across many teams |
| Refactor reversibility | High | High | Low |
Two rows deserve emphasis. "Refactor reversibility" is high for both monolith styles because everything lives in one repository and one process: you can move a boundary in an afternoon. Once a boundary becomes a network call with its own database and deployment pipeline, reversing it is a project. And "latency overhead" is the silent tax of microservices: a request that touched three in-process modules now touches three services across the wire, each adding serialization, network, and retry cost.
Pick the pattern by answering ordered questions, not by counting how many services your competitor has. Work top to bottom and stop at the first honest "yes" that forces your hand. The default destination, if nothing forces you elsewhere, is a modular monolith.
Score your situation against the criteria below. The more of these you can answer "yes" to with evidence rather than aspiration, the more microservices start to earn their cost.
| Decision criterion | Points to monolith / modular | Points to microservices |
|---|---|---|
| Engineering headcount | Under 30 engineers | Many teams, 40+ engineers |
| Domain clarity | Boundaries still shifting | Boundaries stable and well understood |
| Scaling profile | Whole app scales together | One component dominates load |
| Deployment friction | Teams rarely block each other | Teams blocked by shared release train |
| Operational maturity | Limited platform/SRE capability | Strong platform engineering in place |
| Compliance isolation | One trust boundary is fine | Hard data-isolation requirements |
| Independent lifecycles | Components change together | Components evolve at different speeds |
The pattern in this table is consistent: microservices pay off when the constraint is organizational, not technical. If your real problem is "fifty engineers keep stepping on each other in one release pipeline," services help. If your real problem is "the app is slow" or "the code is messy," services will make both worse before they make anything better.
Martin Fowler's MonolithFirst principle is the spine of this framework. The advice is simple: almost all the successful microservices stories he observed started as monoliths that grew too big and were broken up, while almost all the systems built as microservices from scratch ran into serious trouble [3]. You do not yet understand your domain boundaries well enough on day one to draw service lines correctly. Draw them in code first, where mistakes are cheap, and harden them into services later.
The corollary is that a modular monolith is not a compromise you settle for. It is the deliberate first stage of a sound microservices strategy, because clean modules are exactly what you later promote to services. If you cannot keep modules clean in one process, you have no chance of keeping services clean across a network.
Every architecture trades one kind of pain for another. The honest version of the trade-off looks like this. A monolith trades long-term team scalability for short-term simplicity and speed. Microservices trade short-term simplicity for long-term team scalability, and you pay the complexity premium every single day in between. A modular monolith defers that trade: you keep the simplicity now and preserve the option to split later, at the cost of disciplined boundary enforcement that some teams will not maintain without tooling.
There is no free lunch. The modular monolith's risk is human, not technical: boundaries erode when deadlines hit unless you enforce them with module systems, build rules, or architecture tests. The microservices risk is structural: you can do everything right and still drown in operational overhead if your platform capability has not matured to match. Choose the risk you can actually manage.
Here is a modular monolith laid out so the boundaries are visible. Each module owns its schema. Cross-module access goes through interfaces, never direct table reads. This is the shape you want before you split anything.
+---------------------------+
HTTP / API -->| API Gateway |
| (routing, auth, rate) |
+-------------+-------------+
|
+-------------v-------------+
| Modular Monolith (1 proc)|
| |
| [Orders] [Billing] |
| [Catalog] [Identity] |
| |
| modules talk via |
| in-process interfaces |
+----+------+------+------+--+
| | | |
+---v--+ +-v---+ +v----+ +v-----+
|Orders| |Bill | |Cat. | |Ident.|
| DB | |DB | |DB | |DB |
+------+ +-----+ +-----+ +------+
Promotion path: when [Billing] needs independent scaling
or its own deploy cadence, lift it out as a service. Its
data and interface are already isolated, so the move is
a deployment change, not a redesign.
The point of the diagram is the promotion path. Because Billing already owns its data and exposes a narrow interface, turning it into a service later is mechanical. You are not unpicking a tangle. You are cutting a clean seam that you drew on purpose. That is the entire payoff of doing the modular work up front.
The most instructive 2026-era story is from Amazon Prime Video's own engineering team. In 2023 they published an account of rebuilding their audio and video quality monitoring service. It had been built as a distributed system using serverless functions and microservices-style components. At scale, the orchestration and the data passed between components became the bottleneck and the cost driver. They consolidated the components into a single process, a monolith, and reported a cost reduction of more than 90 percent while also raising the scaling ceiling.
The lesson is not "microservices are bad" or "Amazon abandoned microservices." Amazon runs an enormous microservices estate. The lesson is that a specific workload, with high-volume data passing between fine-grained components, was a poor fit for the distributed pattern, and a team senior enough to admit it moved back. Size the pattern to the workload. The willingness to reverse an architecture decision when the evidence arrives is a sign of engineering maturity, not failure.
Set this against the broader signal from ThoughtWorks, whose Technology Radar positions microservices as a technique to Trial rather than a default to adopt, precisely because so many teams reach for them before they have the organizational or operational scale to justify the cost [2]. The industry has stopped treating microservices as the automatic answer.
If there is one outcome worse than a messy monolith, it is a distributed monolith. This is what you get when you split a system into services but leave them tightly coupled: services that must be deployed together, that share a database, that call each other synchronously in long chains, and that fail as a unit. You have paid the full microservices tax, network latency, operational overhead, distributed debugging, and received none of the benefit, because nothing is actually independent.
The defense is sequencing. Enforce clean module boundaries inside a monolith first and prove that modules can evolve independently in code. Only then promote a module to a service. If a module cannot live without reaching into another module's data while still in one process, splitting it across a network will not fix the coupling. It will just hide the coupling behind latency and make it lethal. The distributed monolith is almost always the result of splitting deployment before splitting design.
Architecture is migrated, not declared. The roadmap below moves a team from a starting monolith toward selective services without ever passing through the distributed-monolith trap. Each phase has an exit criterion: do not start the next phase until the current one is genuinely complete.
| Phase | Focus | Key actions | Exit criterion |
|---|---|---|---|
| 1. Foundation | Clean monolith | Establish CI/CD, automated tests, observability, single deploy | Reliable one-click deploys, green test suite |
| 2. Modularize | Internal boundaries | Define modules, isolate per-module schemas, enforce via architecture tests | No cross-module table access; module interfaces only |
| 3. Measure | Evidence gathering | Find real scaling, deploy-contention, and team-friction hotspots | Documented case for which module to extract and why |
| 4. Extract | First service | Promote the highest-pressure module to a service; add async messaging where needed | Service deploys independently, owns its data |
| 5. Operate | Platform maturity | Distributed tracing, contract tests, on-call, SLOs, golden paths | Mean time to recovery acceptable; teams unblocked |
Notice that you do not reach "extract a service" until phase four, and only for a module that measurement, not intuition, has flagged. Many organizations discover that phases one through three solve their problem entirely, and phase four never becomes necessary. That is a successful outcome, not an unfinished one.
Most architecture failures are not exotic. They are a handful of predictable mistakes repeated across the industry. Recognizing them is cheaper than living through them.
A useful filter: if the honest reason for an architecture choice is fear of looking outdated, stop. Fashion is the most expensive input into a system design.
Architecture choices are budget choices, and microservices carry costs that rarely appear in the original proposal. The table below contrasts where the money goes. Treat the figures as directional, not quoted: the relative shape matters more than any single number.
| Cost category | Modular monolith | Microservices |
|---|---|---|
| Compute and hosting | Low, scales as one unit | Higher, per-service overhead and redundancy |
| Network and data transfer | Negligible (in-process) | Significant, every hop crosses the wire |
| Observability tooling | Standard logging and metrics | Distributed tracing, higher tooling spend |
| Operational headcount | Small; one deploy to run | Platform and SRE teams required |
| Onboarding and cognitive load | One codebase to learn | Many services, contracts, and runbooks |
| Incident and downtime risk | Fewer moving parts | More failure modes between services |
The Prime Video case made the compute and data-transfer line concrete: the bulk of the cost came from orchestration and from moving data between fine-grained components, and removing those boundaries removed the cost. The category most teams underestimate, though, is operational headcount. Microservices effectively require a platform engineering capability, and that team is a permanent line item, not a one-off. If you cannot fund it, you cannot afford the architecture.
The clearest way to control architecture cost is to be deliberate about build versus buy. The rule is simple: buy the plumbing, build the domain. Your competitive advantage lives in your domain logic, the orders, billing, pricing, and workflows that are unique to your business. Everything underneath that, the cloud, the orchestration, the message bus, the observability stack, and increasingly the internal developer platform, is undifferentiated infrastructure that you should rent.
This is where an outcome-focused partner fits naturally. Teams like Mind Supernova, a Vietnam-based software engineering partner founded in 2023, help enterprises do exactly this kind of structured modularization and selective extraction: senior engineers, async-first with 4+ hours daily UK overlap, who can start in 5 to 7 days. Whether you use the model of staff augmentation to add senior engineers to an existing team or a dedicated team to own a workstream end to end, the build-versus-buy line should stay the same. Buy the commodity, build the differentiator, and bring in help where capacity is the constraint. If you want a second opinion on your own architecture, you can schedule a call with our engineering team.
Architecture does not stand alone. The pattern you choose sets the requirements for the platform and pipelines around it. If you do move toward services, the supporting capabilities have to mature in step, which is why platform engineering and delivery pipelines belong in the same conversation as architecture.
If artificial intelligence features are part of your roadmap, the architecture choice also shapes how you integrate them. Patterns such as those in enterprise RAG systems for secure, reliable AI tend to slot in cleanly as a module or a dedicated service depending on scale, and the same build-versus-buy thinking applies. For teams weighing external help on the AI side specifically, the guidance in how to choose an AI outsourcing partner without getting burned mirrors the partner advice above: keep the differentiated work in-house and buy capacity for the rest.
No. Microservices remain the right pattern for large organizations with many teams and stable domain boundaries. What has changed is the default: teams no longer reach for them automatically. ThoughtWorks lists microservices as Trial, not adopt, and most systems are better served starting as a modular monolith and extracting services only when scale demands it.
A modular monolith is a single deployable application with strictly enforced internal module boundaries. Each module owns its data and exposes a narrow interface. You get the operational simplicity of one deploy with the architectural discipline of services, plus a clean path to extract modules into services later if scale requires it.
For one specific workload, their quality monitoring service, the serverless and microservices design made orchestration and data transfer between components the main bottleneck and cost. Consolidating into a single process cut cost by more than 90 percent and raised the scaling ceiling. Amazon still runs microservices broadly; they sized the pattern to the workload.
A distributed monolith is the worst of both worlds: services that look independent but are tightly coupled. They deploy together, share a database, and call each other in long synchronous chains. You pay the full operational cost of microservices and gain none of the independence. It usually results from splitting deployment before splitting design.
Split when evidence, not intuition, forces it: a single module dominates scaling, teams are blocked by a shared release train, or components need genuinely independent lifecycles. First isolate the module's data and interface inside the monolith. If it cannot live independently in one process, it will not survive a network boundary.
The defensible 2026 default is a well-factored modular monolith, with microservices reserved for the organizational scale that genuinely needs them. Start simple, keep your boundaries clean, measure before you split, and treat the network as a one-way door. The Prime Video reversal and the ThoughtWorks Trial rating both point the same way: match the pattern to the workload and the team, not to the conference circuit.
This quarter: audit your current system honestly. Are your boundaries clean enough to extract a service, or would splitting today produce a distributed monolith? Run the decision framework in this guide against your real headcount and scaling profile.
Next 90 days: if you are starting fresh, build a modular monolith with isolated per-module schemas and architecture tests that enforce the boundaries. If you are migrating, complete the foundation and modularize phases before extracting a single service. If capacity is the constraint, talk to our engineering team about adding senior engineers who can do this work alongside yours. The right architecture is the one your team can build, run, and afford.
AI-powered ERP moves beyond automation to decision intelligence: agents in ERP, the data foundation required,...

How AI is reshaping the enterprise SDLC across plan, design, code, test, release, and operate, with productivi...

Coding assistants are only the first step. Learn how AI-powered software development now spans the entire SDLC...