
How Multimodal AI Is Handing Global Enterprises a New Competitive Edge in 2026
Multimodal AI reads text, images, audio, and video together. Learn the enterprise use cases and the competitiv...
A practical, layer-by-layer reference architecture for the modern enterprise AI stack in 2026, with technology choices, build-vs-buy guidance, and an adoption roadmap.
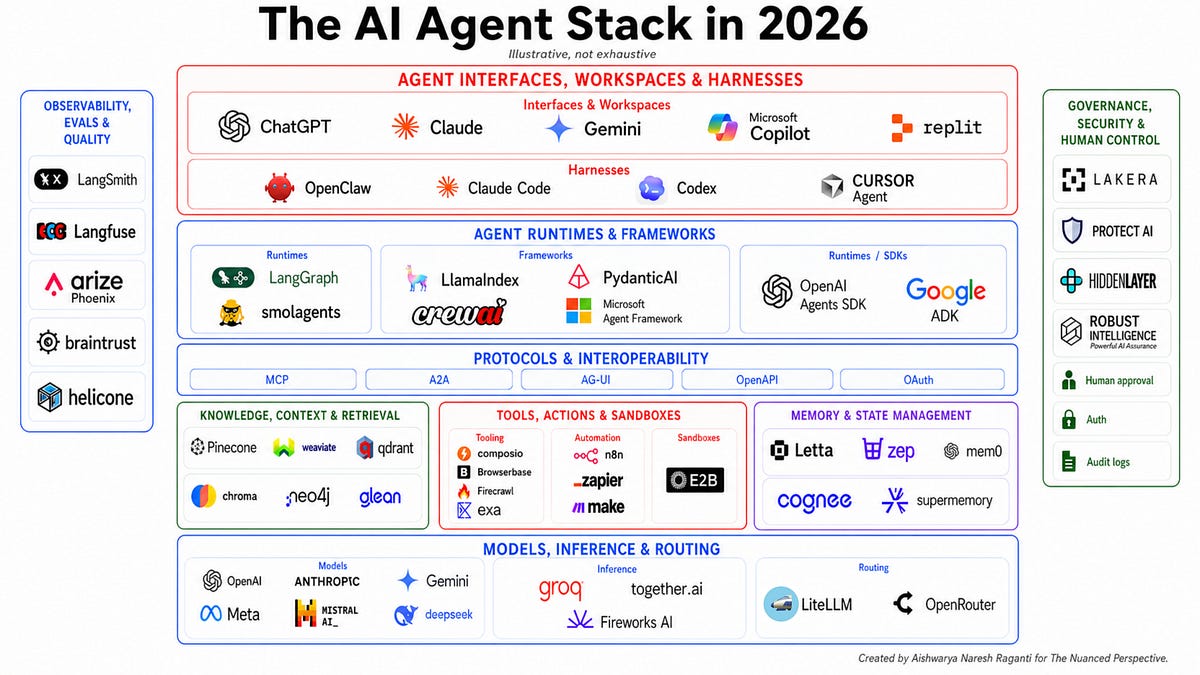
The enterprise AI stack is the layered set of compute, models, data, orchestration, application, and governance components that an organization assembles to build, run, and control AI systems in production. In 2026 it is no longer a single platform you buy or a model you call. It is an architecture you design, with deliberate choices at every layer that determine cost, reliability, security, and how fast your teams can ship.
Two years ago, most enterprise AI architectures fit on a napkin: an application calling a foundation model API, with a vector database bolted on for retrieval. That picture is now obsolete. The modern stack has grown new, distinct layers, a model gateway in front of every provider, an agent orchestration tier with first-class memory, an evaluation and observability discipline borrowed from MLOps, and a cross-cutting governance and FinOps fabric that touches everything. Industry analysts at Gartner have noted that AI gateways alone moved from emerging technology to essential infrastructure inside a single year.
This article is a reference architecture, not a product roundup. It walks each layer of the stack in order, explaining what the layer does, the realistic technology choices, and where the build-versus-buy line usually falls for an enterprise. The goal is to give CTOs, enterprise architects, and Heads of AI a shared mental model they can use to evaluate their own estate, spot the gaps, and avoid the two failure modes that sink most programs: uncontrolled tool sprawl and deep vendor lock-in.
Key Takeaways
The enterprise AI stack in 2026 is best understood as six horizontal layers, infrastructure, model, data and retrieval, orchestration and agents, and application, with a sixth cross-cutting layer for the operational concerns that span all of them: LLMOps and observability, security and guardrails, governance, and FinOps. Each layer has a clear job, and a clean separation between them is what lets you swap a model, change a vector store, or add an agent framework without rewriting everything above and below.
The reason this layering matters is architectural decoupling. When the boundaries between layers are explicit and enforced through interfaces, the rapid churn in any single layer, and every layer churns fast right now, stays contained. When the boundaries blur, you end up with an application that hard-codes a specific model provider, a retrieval pipeline tangled into business logic, and a stack you cannot evolve. The table below is the reference map for the rest of this article.
| Layer | What it does | Representative technology choices (2026) | Typical build vs. buy |
|---|---|---|---|
| 1. Infrastructure & compute | Provides GPU/accelerator capacity, inference serving, and the cloud or on-prem substrate | Hyperscaler GPU instances, neoclouds, managed inference, vLLM/TensorRT-LLM serving, quantization | Buy capacity; standardize serving |
| 2. Model layer | Supplies reasoning capability via foundation models, fine-tunes, and embeddings, routed through a gateway | Closed APIs, open-weight models, fine-tuning/LoRA, embedding models, model gateway/router | Buy models; build the routing/policy |
| 3. Data & retrieval | Grounds models in proprietary knowledge and structured features | Modern data platform/lakehouse, vector databases, RAG pipelines, feature stores | Buy stores; build the retrieval logic |
| 4. Orchestration & agents | Coordinates multi-step reasoning, tool use, and memory across systems | Agent frameworks, MCP/A2A protocols, tool registries, tiered memory | Buy frameworks; build the workflows |
| 5. Application & experience | Delivers AI to users and embeds it into products and workflows | Copilots, chat surfaces, embedded features, API/SDK access, human-in-the-loop UIs | Build, this is your differentiation |
| 6. Cross-cutting | Operates, secures, governs, and pays for everything above | LLMOps/eval, observability, guardrails, governance, FinOps for AI | Buy tooling; build the policy |
For the data-platform foundation that layer three depends on, our deeper treatment lives in modern data platforms for AI-driven organizations. The rest of this article unpacks each layer in turn.
The infrastructure layer supplies raw accelerator capacity and the serving runtime that turns a model into a low-latency endpoint. It is the foundation everything else sits on, and in 2026 it is also where the largest and most volatile portion of the AI bill lives.
The first decision is sourcing. Most enterprises consume GPU capacity from hyperscalers for integration and governance, supplement with specialized GPU clouds (the so-called neoclouds) for cheaper bulk training and batch inference, and reserve on-premises clusters for data-residency or latency-critical workloads. A recurring trap is over-committing: neoclouds increasingly require multi-year reservation windows, so capacity planning is now a procurement discipline, not an afterthought.
The second decision is the serving runtime. Open serving stacks such as vLLM and TensorRT-LLM have become the default for self-hosted inference, and quantization is the highest-leverage cost lever available. Moving from FP16 to FP8 on current-generation hardware typically yields a meaningful throughput gain, often in the range of 1.3x to 2x, at a small and usually acceptable quality cost on instruction-tuned models. The practical sequence for cost control is well established: optimize the model first (a smaller or quantized model changes every downstream dollar), then the runtime, then the infrastructure shape (spot instances, autoscaling), with FinOps running continuously underneath.
Build vs. buy. Almost no enterprise should build its own GPU data center. Buy capacity, but standardize on a portable serving runtime so you are not locked to one provider's managed inference. The differentiation here is operational discipline, right-sizing, autoscaling, and quantization, not owning the metal.
The model layer provides the reasoning capability of the stack through three components: foundation models, fine-tuned variants, and embedding models, all increasingly fronted by a model gateway. The defining architectural shift of 2026 is that no serious enterprise calls model providers directly from application code anymore.
The realistic posture is portfolio, not monogamy. Closed, frontier API models (from providers such as OpenAI, Anthropic, and Google) lead on the hardest reasoning and agentic tasks and require no infrastructure to operate. Open-weight models give you control, data residency, predictable per-token economics at scale, and the ability to fine-tune freely. Most mature enterprises run both, frontier models for complex, low-volume reasoning and open or smaller models for high-volume, well-scoped tasks where the cost difference compounds.
Fine-tuning, usually via parameter-efficient methods like LoRA, earns its place for tone, format, and narrow-domain accuracy, but it is not a substitute for retrieval when the need is fresh or proprietary knowledge. The honest decision rule, which we cover in depth elsewhere, is that retrieval handles knowledge that changes and fine-tuning handles behavior that should not. Embedding models are the quiet workhorses, the quality of your embeddings sets the ceiling on retrieval quality, so they deserve the same evaluation rigor as your generative models.
A model gateway sits between your applications and every model provider, handling routing, authentication, rate limiting, cost tracking, semantic caching, fallback, and a single enforcement point for guardrails. Gartner's 2025 generative AI assessment moved AI gateways from emerging to essential, and the reasoning is simple: without a gateway, every cost policy, every provider migration, and every security control has to be re-implemented in each application. With one, you get multi-model routing (send each request to the cheapest model that meets the quality bar), provider fallback during outages, and an instant kill switch.
The competitive landscape splits into open-source options such as LiteLLM, which support 100-plus providers behind an OpenAI-compatible interface with virtual-key budgeting, and governance-focused commercial gateways such as Portkey (acquired by Palo Alto Networks in 2026), which add guardrails, semantic caching, and prompt management. The choice depends on whether your dominant constraint is self-hosting flexibility or built-in policy enforcement.
Build vs. buy. Buy the foundation models and buy a gateway, do not build a gateway from scratch, it is undifferentiated heavy lifting. But own the routing policy and the model-selection logic, because that is where your cost and quality trade-offs are encoded.
The data and retrieval layer grounds the model in your proprietary, current, and structured knowledge. It is the difference between a generic assistant and a system that knows your contracts, your catalog, and your customers. Retrieval-augmented generation, RAG, is the dominant enterprise pattern for this, and it has matured from a single trick into a stack of its own.
Retrieval is only as good as the data feeding it. A modern lakehouse or data platform, with reliable pipelines, governance, and lineage, is the precondition for trustworthy AI, which is why we treat it as a separate discipline in modern data platforms for AI-driven organizations. Garbage in, hallucination out, no amount of prompt engineering compensates for a broken data foundation.
A vector database stores the embedding representations of your content and serves the semantic-similarity search at the heart of RAG. The strongest engines in 2026 combine vector search with keyword (BM25) search and multimodal retrieval in a single hybrid index, because pure vector search alone misses exact-match queries that keyword search handles trivially. Around the store sits the pipeline: chunking, embedding, hybrid retrieval, re-ranking, and context assembly. The retrieval logic, how you chunk, what you re-rank, how you handle access control on retrieved documents, is where most of the engineering value and most of the failure modes live.
Done well, enterprise RAG is the single most reliable way to reduce hallucination and keep answers current without retraining. We unpack the security and reliability patterns in enterprise RAG systems, including the document-level permissioning that keeps a chatbot from leaking data its user should never see.
Not all enterprise context is unstructured text. A feature store serves the structured, real-time signals, account status, risk scores, recent behavior, that agents need to make grounded decisions. In high-stakes domains like finance and fraud, the feature store is as important as the vector database.
Build vs. buy. Buy the vector database and the feature store, building either is a multi-year distraction. Build the retrieval pipeline, because chunking strategy, hybrid weighting, re-ranking, and permission enforcement are specific to your data and your risk posture.
The orchestration layer coordinates multi-step reasoning, tool calls, and memory so that AI can complete tasks rather than just answer questions. By 2026, agent orchestration is a structural requirement of the enterprise stack: agents introduce stateful logic, tool execution, and task delegation into what used to be a stateless request-response world.
Three open frameworks dominate the enterprise conversation, and the right choice follows a single decision rule: identify the dominant constraint and pick the framework whose core abstraction matches it. LangGraph, with its graph-based execution, has become the most battle-tested for production stateful systems where you need explicit control, audit trails, and rollback points. CrewAI offers the lowest barrier for role-based business workflows and rapid prototyping. Microsoft consolidated AutoGen and Semantic Kernel into the unified Microsoft Agent Framework, which reached general availability in 2026, making AutoGen itself a legacy path. The pattern to internalize: for production-grade, auditable agent systems, frameworks built around explicit state and control are winning.
The protocol layer is what keeps the agent tier from collapsing into a tangle of bespoke integrations. The Model Context Protocol (MCP) and the Agent-to-Agent (A2A) protocol moved from proprietary specifications to neutral, foundation-stewarded standards, and every major framework now supports MCP natively or through adapters. MCP gives agents a standard way to discover and call tools and data sources; A2A lets agents from different vendors and teams cooperate. Standardizing on these protocols is the single most effective defense against tool sprawl and lock-in, which is why we wrote a full primer on MCP as the enterprise AI standard.
The biggest conceptual change in the agent layer is memory. In 2024, memory meant pick a vector database and do RAG. In 2026, memory is a distinct architectural primitive with tiers: short-term working memory within a task, session memory across a conversation, and long-term memory persisted across sessions. Conflating memory with retrieval is a common design error, retrieval pulls in external knowledge, while memory persists the agent's own state and learnings.
Build vs. buy. Buy the framework, building your own orchestration engine is rarely justified. Build the workflows, the agent topologies, the tool definitions, the human-in-the-loop checkpoints, because those encode your actual business processes. For the investment-decision framing of where to place agentic bets, see our CTO guide to agentic AI strategic investments.
The application layer is where AI meets users and embeds into products, and it is the one layer that should be overwhelmingly built, not bought, because it is your differentiation. Everything beneath it is increasingly commoditized infrastructure; the experience you deliver on top is what customers and employees actually see and value.
This layer spans internal copilots that sit inside the tools employees already use, customer-facing assistants embedded in your product, autonomous back-office agents that run workflows end to end, and API or SDK surfaces that expose AI capabilities to other systems. Two design principles separate good application layers from fragile ones. First, design for human-in-the-loop from the start: confidence thresholds, escalation paths, and review queues are features, not afterthoughts, especially in regulated domains. Second, treat the AI feature like any other product surface, with versioning, A/B testing, and rollback, rather than a magic box wired directly to a model.
Build vs. buy. Build it. The whole point of getting the lower layers right is to make this layer fast and cheap to build and iterate on.
The cross-cutting layer is the operational fabric that runs through every other layer, and skipping it is the fastest route to a stalled program. It has four concerns that have to be designed in, not retrofitted.
LLMOps has evolved from simple model deployment into full-stack agent operations, version control for prompts, structured tracing of every request and tool call, and continuous evaluation. The non-negotiable discipline is that cost tracking and quality measurement must be instrumented together. Measuring cost-per-token without a quality gate produces the classic trap of optimizing yourself into a cheaper, worse system. Every request should be traced and tagged so you can attribute cost and quality to a model, an endpoint, a dataset, and a customer.
Guardrails are the policies, content filtering, topic restrictions, PII handling, prompt-injection defenses, that run on every request before and after it touches a model. The gateway is the natural enforcement point so the same policy applies across providers. New attack surfaces, prompt injection through retrieved documents, tool-call abuse by agents, demand controls that traditional application security does not cover.
Governance establishes who can deploy what, against which data, under which approvals, and how that maps to regulations like the EU AI Act. The architectural requirement is a model and use-case registry that ties every production AI system to an owner, a risk classification, and an audit trail. Governance that lives in a slide deck instead of the stack does not survive contact with an auditor.
AI cost behaves differently from traditional cloud spend because it scales with usage in ways that can surprise teams overnight, the great token panic, as one industry event in 2026 dubbed it. A majority of FinOps teams now directly manage AI spend. The core practices are tagging every dimension (compute, model, endpoint, dataset, customer), routing requests to the cheapest acceptable model via the gateway, applying semantic caching, and using quantization, spot capacity, and autoscaling at the infrastructure layer. If it isn't tagged, you can't optimize it.
The right sequence is foundations before scale: establish the gateway, data, and evaluation layers before you proliferate agents and applications. Programs that invert this order, building flashy agents on top of an ungoverned, unmeasured base, are the ones that produce impressive demos and unshippable products. A practical phased roadmap looks like this.
The strategic payoff of this sequence is compounding: each layer you harden makes the next application faster to build, which is the entire economic argument for treating AI as a platform rather than a series of one-off projects.
The two failure modes that derail more programs than any technical limitation are tool sprawl and vendor lock-in. Both are governance failures disguised as technology choices.
The practical reality is that most enterprises lack the in-house depth to assemble all six layers quickly, and the talent market for production LLMOps, RAG, and agent engineering remains tight. The decision is rarely all-build or all-buy. The durable pattern is to own your differentiators, the application layer, the retrieval logic, the agent workflows, and the governance policy, while buying commodity infrastructure and partnering for the specialized engineering that accelerates the build.
This is where an experienced delivery partner earns its place. As an Enterprise AI Engineering partner, Mind Supernova helps organizations design the reference architecture, stand up the gateway, data, and evaluation foundations, and build production RAG and agent systems, then hand the keys back to internal teams rather than creating a new dependency. The objective is to compress the months it takes to get layers one through four production-ready, while leaving your team owning the layer-five experience that differentiates you.
For leaders deciding where to invest, four recommendations carry the most weight:
The enterprise AI stack is the layered set of technologies an organization uses to build and run AI in production: infrastructure and compute, the model layer, data and retrieval, orchestration and agents, the application layer, and a cross-cutting layer for LLMOps, security, governance, and FinOps. In 2026 it is an architecture you design, not a single product you buy.
A model gateway is an intermediary between your applications and AI model providers that handles routing, authentication, rate limiting, cost tracking, caching, fallback, and guardrail enforcement. Enterprises need one because it centralizes cost and security policy and lets you switch or combine providers without rewriting application code, which is why analysts now class it as essential infrastructure.
RAG (retrieval-augmented generation) pulls in external, proprietary knowledge to ground a model's answer, while agent memory persists the agent's own state, working context within a task, session context across a conversation, and long-term memory across sessions. They are distinct primitives, and conflating them is a common design error.
Most mature enterprises use both. Closed, frontier API models lead on the hardest reasoning and require no infrastructure, while open-weight models offer control, data residency, and better per-token economics at scale. The practical posture is a portfolio routed through a gateway: frontier models for complex low-volume work, smaller or open models for high-volume scoped tasks.
The Model Context Protocol (MCP) is an open standard that gives AI agents a consistent way to discover and call tools and data sources. It sits in the orchestration layer and is now supported by every major agent framework. Standardizing on MCP is one of the most effective ways to avoid tool sprawl and vendor lock-in.
Through FinOps for AI: tag every cost dimension (compute, model, endpoint, dataset, customer), route requests to the cheapest acceptable model via the gateway, apply semantic caching, and use quantization, spot capacity, and autoscaling at the infrastructure layer. Crucially, track cost and quality together so optimization does not silently degrade the product.
Scaling agents and applications before the foundations, gateway, data, retrieval, and evaluation, are in place. This produces impressive demos that cannot be safely shipped or governed. The reliable sequence is to harden the lower layers first, then add autonomy on top of a proven, measured base.
The enterprise AI stack of 2026 is a layered architecture, and the organizations that win treat it like one. They decouple their layers so they can swap any component as the market churns, they buy the commodity layers and build their differentiators, and they fund the unglamorous cross-cutting disciplines, evaluation, security, governance, and FinOps, that turn demos into durable products. The two failure modes to design against are tool sprawl and vendor lock-in, and the defense against both is the same: a thin set of standards, open protocols, and an exit path at every layer.
If your team is mapping its own stack against this reference architecture and deciding where to build versus where to bring in help, Mind Supernova works with enterprise architecture and platform teams as an AI engineering partner to design and stand up these layers and then hand ownership back to your people. Wherever you start, start with the foundations, the gateway, the data, and the evaluation harness, because every layer you get right makes the next one cheaper.
Multimodal AI reads text, images, audio, and video together. Learn the enterprise use cases and the competitiv...

? The Enterprise AI Standard Explained for 2026")
What is MCP? A clear, technical guide to the Model Context Protocol — the open standard that connects AI apps...