
Enterprise AI Adoption in 2026: The Trends, Hard Numbers, and Costly Mistakes to Avoid
The 2026 enterprise AI adoption trends that matter: top use cases, barriers, ROI, build vs buy, and the talent...
How enterprises build production AI agents: architectures, use cases, governance, and when to outsource agentic AI development.
AI agent development for enterprises is the practice of building software systems that use large language models to reason, plan, call tools, and complete multi-step tasks with limited human supervision. Unlike a chatbot that only answers questions, an enterprise AI agent can read a ticket, query a database, draft a reply, update a CRM record, and escalate edge cases on its own. That shift from "answer the question" to "do the work" is why agentic AI has become the defining enterprise software project of 2026.
It's also harder than it looks. An agent that hallucinates a refund, calls an API with the wrong arguments, or leaks a customer record is a liability, not a productivity win. Getting agents into production safely takes orchestration design, retrieval pipelines, memory, evaluation harnesses, and governance that most internal teams are building for the first time.
This guide covers what enterprise AI agents actually are, the core architectures (tool use, orchestration, RAG, and memory), the use cases that pay back fastest, how to decide between building in-house and outsourcing, and the governance and security controls you need before you ship. If you're scoping a delivery partner, Mind Supernova, a Vietnam-based engineering company founded in 2023, builds agentic systems as part of a broader AI engineering practice, and the cost and team-access points below apply whoever you choose.
Key Takeaways
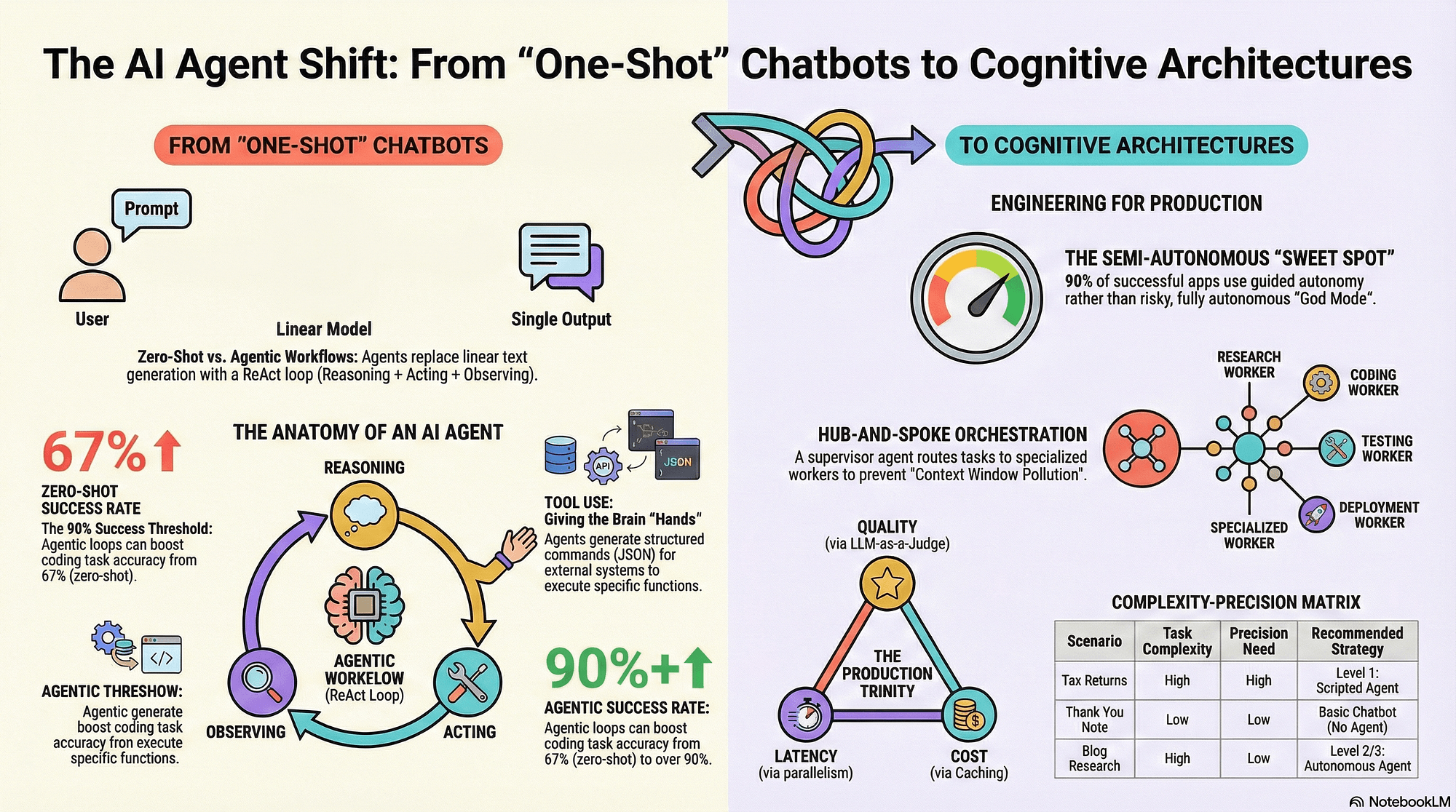
An AI agent is a system built around a language model that can perceive context, decide what to do next, take an action through a tool, observe the result, and repeat until a goal is met. The model supplies reasoning. The surrounding software supplies the tools, the data, the guardrails, and the loop. Strip away the hype and an agent is a reasoning engine wired to your systems with a control layer that decides when to act and when to stop.
The practical distinction enterprises care about is autonomy. A traditional automation runs a fixed script. An agent chooses its own path at runtime based on what it observes. That flexibility is the value and the risk. It can handle messy, variable inputs no flowchart anticipated. It can also do something you never intended unless its actions are scoped and checked.
These terms get used loosely, so it helps to separate them. An assistant responds to prompts and may fetch information, but a human drives every step. A workflow is a deterministic chain of model calls and code where the steps are fixed in advance. A true agent decides the steps itself, including which tools to call and in what order. Many "agents" in production are actually well-designed workflows with a single decision point, and that's often the safer choice. Start with the least autonomy that solves the problem.
Nearly every production agent is assembled from four building blocks. Understanding them lets you scope a project accurately and ask a vendor the right questions.
Tool use is how an agent acts on the world. The model is given a set of functions it can call, each with a name, a description, and a typed schema for its arguments. When the model decides a tool is needed, it returns a structured call, your code executes it, and the result goes back into the conversation. Tools might query a database, hit an internal API, send an email, or run a calculation. The quality of your tool definitions matters more than the prompt: clear descriptions and strict argument validation prevent most misfires.
Orchestration is the control layer that runs the reasoning loop and decides how work is divided. A single-agent design keeps one model in charge of the whole task, which is simpler to debug and cheaper to run. A multi-agent design splits work across specialized agents, for example a planner, a researcher, and a writer coordinated by an orchestrator. Multi-agent systems handle complex tasks better but cost more in tokens and latency and are far harder to evaluate. Most teams should ship a strong single agent first and only add agents when a clear bottleneck demands it.
RAG grounds the agent in your data so it answers from your documents instead of its training memory. The pattern: index your content into a vector store or hybrid search index, retrieve the most relevant chunks at query time, and inject them into the model's context. Done well, RAG cuts hallucination, keeps answers current, and lets you cite sources. Done poorly, it retrieves the wrong chunks and the agent confidently summarizes garbage. Retrieval quality, chunking strategy, and re-ranking are where most RAG projects succeed or fail.
Memory lets an agent stay coherent across many steps and across sessions. Short-term memory is the working context for the current task. Long-term memory persists facts, preferences, and prior outcomes in a store the agent can read and write, often the same vector index used for RAG. Without memory, an agent forgets what it did two steps ago. With unbounded memory, context windows overflow and costs spike. Good memory design summarizes, prunes, and scopes what the agent remembers.
The table below maps these blocks to what they solve and where they typically break.
| Building blockWhat it providesCommon failure mode | ||
| Tool use / function calling | Ability to take actions in real systems | Wrong arguments, unvalidated inputs, unintended side effects |
| Orchestration | Control of the reasoning loop and task division | Multi-agent sprawl, runaway loops, untraceable decisions |
| RAG / retrieval | Grounding in current, proprietary data | Poor chunking and re-ranking, retrieving irrelevant context |
| Memory / state | Coherence across steps and sessions | Context overflow, stale facts, ballooning token cost |
These architectures connect directly to adjacent AI work. Grounding quality depends on clean data, which is why annotation and pipelines matter, and behavior on niche tasks often improves with model adaptation covered in our guide to LLM fine-tuning services explained.
Agents earn their keep where work is high-volume, rule-bound enough to verify, and currently eating skilled hours. A few categories consistently deliver first.
The pattern across all of these is the same. The agent handles the volume, a human owns the exceptions, and every consequential action is logged and reversible. McKinsey's State of AI research shows a large majority of organizations now use or pilot generative AI, and agentic workflows are where that adoption is heading next [1]. For a wider view of where the market is going, see our analysis of enterprise AI adoption trends.
Most agent pilots demo well and then stall. The gap between a slick demo and a system you can trust with real customers is engineering discipline, not a better model.
You cannot improve what you cannot measure. Production agents need an evaluation suite: a set of representative tasks with expected outcomes, scored automatically on every change. Without it, every prompt tweak is a gamble and regressions ship silently. Evaluation is the single most underbuilt part of enterprise agent projects.
When an agent does something wrong, you need to see exactly which tool it called, what it retrieved, and why it decided what it did. Step-level tracing turns a black box into something you can debug. It's also the raw material for your audit log.
Agents can loop, retry, and call expensive models repeatedly. Without budgets, step limits, caching, and model routing (cheap models for easy steps, strong models for hard ones), costs surprise everyone in the first month. Design these limits in from the start.
Agents need the same operational rigor as any production system: versioned prompts and configs, staged rollouts, monitoring, and rollback. This is where data and ML engineering meet platform engineering, and it's a frequent reason teams bring in outside help. You can read more about the full delivery picture in our overview of AI development services in Vietnam.
The honest answer is that build versus outsource is rarely binary. The most successful enterprises keep ownership of strategy, domain knowledge, and the product roadmap, then bring in specialist engineering for the parts that are hard to staff quickly: orchestration, RAG, evaluation, and MLOps.
Build in-house when the agent encodes a core competitive advantage, when you already have a strong AI engineering team with spare capacity, and when the data is so sensitive it cannot leave your environment under any arrangement. Outsource or augment when speed matters, when you lack the specialized skills, or when you want to pilot before committing to a permanent team. A common and sensible middle path is a dedicated team that builds alongside your staff and transfers knowledge as it goes.
| FactorLean build in-houseLean outsource / augment | ||
| Time to first production agent | Slower; hiring and ramp take months | Faster; vetted engineers can start in days |
| Specialized skills (RAG, evals, MLOps) | Must already exist on the team | Brought in immediately |
| Cost structure | Fixed headcount, long commitment | Flexible, scale up or down per phase |
| Strategic control | Maximum | High if you own roadmap and IP terms |
| Best fit | Core, differentiating, highly sensitive systems | Speed, skill gaps, pilots, scaling capacity |
Cost and talent access are why so many enterprises outsource AI engineering to Vietnam. The country has 500,000-plus software developers and over 1.2 million IT professionals, concentrated in Ho Chi Minh City and Hanoi, with 50,000 to 75,000 IT graduates entering the market each year [2]. Senior developer rates run roughly $9-25 per hour versus $75-135-plus in the US and UK, a 30-50% saving against Western markets even after the premium AI and ML engineers command [3]. Attrition sits around 6-8%, well below the 20%-plus often seen in India, which matters for multi-month agent projects where continuity protects quality [4]. Vietnam also ranks #7 on Kearney's Global Services Location Index and top-three in Southeast Asia [5].
For the bigger picture on the model and the market, start with our pillar, AI Outsourcing Vietnam: the complete guide for 2026, and for the startup perspective see why global startups choose Vietnam for AI development. If you'd rather staff up than hand off, our staff augmentation and dedicated team models both apply to agent work.
An agent that can act is an agent that can do harm, so governance is the difference between a sanctioned production system and a liability waiting to happen. Treat every action an agent can take as a permission to be granted deliberately, not a capability to be assumed.
Give the agent the narrowest set of tools and data access it needs for its task, and nothing more. A support agent should not have write access to financial systems. Scope credentials per agent, enforce them at the API layer, and never rely on the prompt alone to keep an agent in its lane. Prompt instructions are guidance, not security.
Some actions should never run fully autonomously: issuing refunds above a threshold, deleting records, sending external communications at scale, or anything irreversible. Route these through human approval. The agent prepares the action, a person confirms it. This single control prevents the majority of catastrophic failures.
Every tool call, retrieval, and decision should be logged with enough detail to reconstruct what happened and why. Audit logs satisfy compliance, enable incident response, and feed your evaluation suite. If you cannot answer "why did the agent do that," you are not ready for production.
Agents introduce attack surfaces that traditional software does not. The most important to defend against:
If you outsource agent development, settle data handling and intellectual property up front: where data is processed and stored, who owns the code and the models, and what security standards the partner meets. A credible partner works inside your environment and signs clear IP and confidentiality terms. For a full evaluation checklist, see our guide on how to choose an AI outsourcing partner, and explore the engineering side at AI development services.
Agent projects fail when teams aim for full autonomy on day one. A staged approach gets value sooner and de-risks the path.
Whether you build this internally or with a partner, the sequence is the same. The teams that ship reliable agents are the ones that treated evaluation and governance as first-class work, not afterthoughts.
A chatbot responds with text and a human drives every step. An AI agent takes actions: it plans, calls tools and APIs, retrieves data, and completes multi-step tasks with limited supervision. The defining difference is autonomy, the agent decides what to do next and executes it, which is also why agents need stronger guardrails.
Usually not at first. Most production agents rely on strong general models plus good retrieval (RAG), clear tool definitions, and prompting. Fine-tuning helps for narrow, repetitive tasks or specialized formats once you have data and a clear gap. Start with RAG and prompting, then fine-tune only if evaluation shows it is needed.
A bounded first agent typically reaches a supervised pilot in a few weeks and full production over a few months, depending on data readiness and integration complexity. The slow parts are rarely the model. They are retrieval quality, evaluation, integrations, and governance sign-off, which is why staged rollout matters.
Yes, with the right terms. Settle data residency, IP ownership, and security standards in the contract, require the partner to work inside your environment, and keep human approval for high-risk actions. A credible partner provides traceability and clear confidentiality terms. The engineering can be outsourced safely while you retain strategic control.
Cost depends on scope, integrations, and team location. Senior engineering rates range from roughly $9-25 per hour in Vietnam to $75-135-plus in the US and UK, so location heavily influences total cost [3]. Budget also for evaluation, MLOps, and ongoing maintenance, which are recurring, not one-time, expenses.
Enterprise AI agents move you from systems that answer to systems that act, and the payoff is real where work is high-volume and verifiable. The teams that succeed do not chase autonomy. They build the four core blocks well, ground agents in clean data, measure everything, and govern every action that matters.
This week: pick one bounded, high-volume use case and write down its success criteria and the actions an agent would need to take. This month: stand up a retrieval foundation and an evaluation harness, then run a human-in-the-loop pilot before widening autonomy. Decide deliberately what to build in-house and what to bring in specialist help for.
If you want senior AI engineers who treat evaluation and governance as first-class work and can start in 5 to 7 days with 4-plus hours of daily UK overlap, Mind Supernova builds agentic systems as a dedicated team or alongside yours. To scope your first agent, schedule a call with our team.
The 2026 enterprise AI adoption trends that matter: top use cases, barriers, ROI, build vs buy, and the talent...

The AI trends reshaping enterprise growth in 2026: agentic AI, multimodal models, RAG, governance, and the AI...

AI agents are automating multi-step workflows across finance, support, IT, and supply chain. Here is how they...