
Data Annotation for Generative AI: The Hidden Engine Behind Models That Actually Work
Data annotation for generative AI: labeling types, RLHF and preference data, quality control, and why teams ou...
Why stateless LLMs need an external memory layer: short-term vs long-term agent memory, how it's built, memory vs RAG, and governance for enterprise AI.
AI memory systems are the external layer that lets large language models retain, retrieve, and reuse information across turns, sessions, and tasks — turning a stateless model into an agent that actually remembers. A raw LLM has no built-in recollection of anything beyond what currently sits inside its context window. The moment that window scrolls past, the conversation ends, or the process restarts, the model forgets. For a casual chatbot demo that is fine. For an enterprise AI agent expected to handle a multi-week procurement workflow, recall a customer's history, or learn a company's internal procedures, statelessness is a fundamental architectural gap.
Most enterprise AI initiatives that stall do so not because the model is weak, but because the system around the model has no durable memory. The agent can reason brilliantly in the moment and then lose every detail the instant the task spans more than one call. Memory is the missing layer that closes that gap. It is what separates a clever autocomplete from a system that accumulates knowledge, adapts to a user, and behaves consistently over time.
This article defines the types of memory an enterprise AI system needs, explains how each is implemented, clarifies the frequently confused relationship between memory and retrieval-augmented generation, and lays out the governance and maturity considerations that decide whether agent memory becomes an asset or a liability. The goal is a practical mental model that engineering and AI leaders can use to design memory deliberately rather than bolting it on after the fact.
Key Takeaways
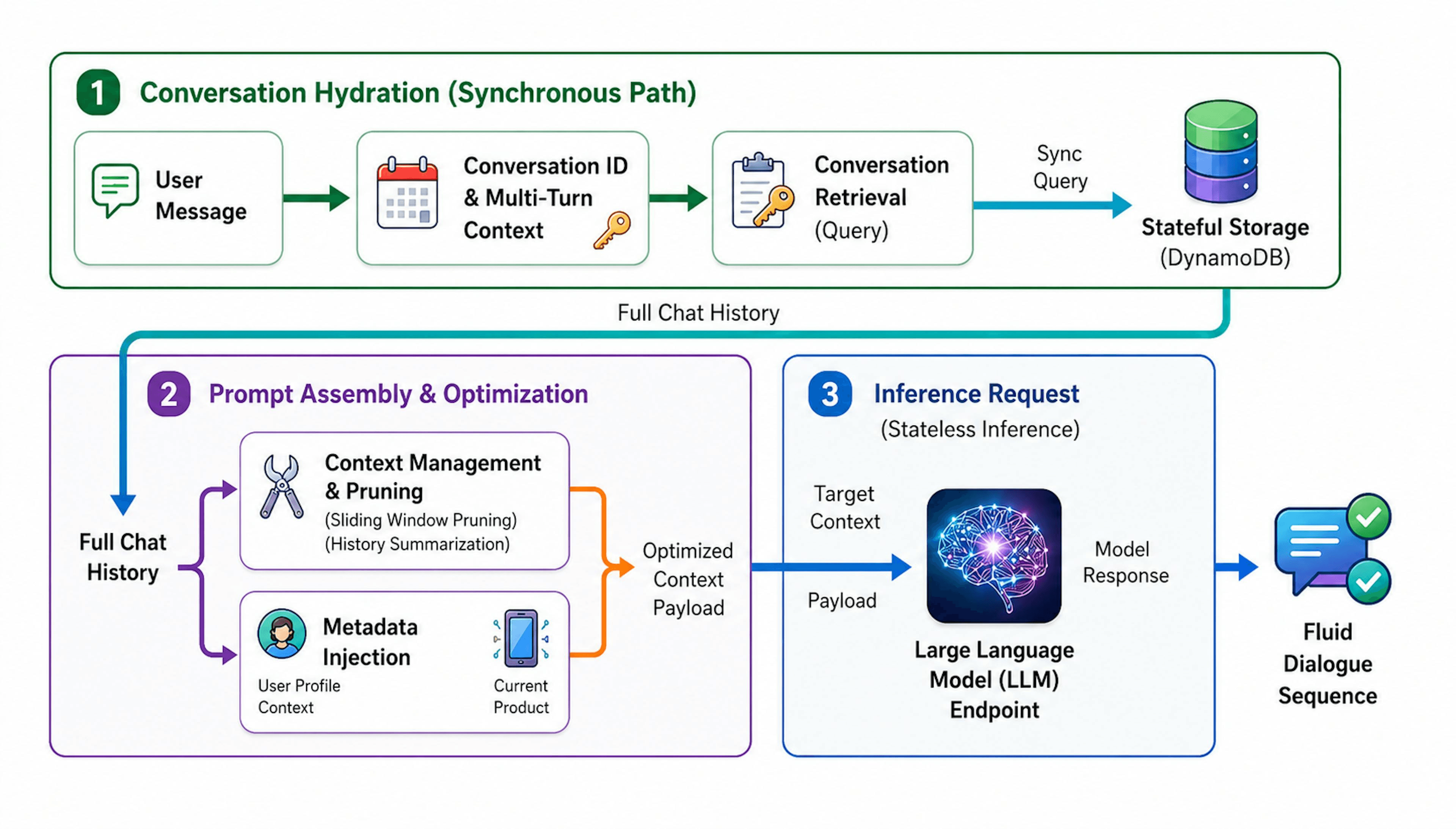
LLMs need external memory because the model itself is stateless: it processes the tokens you give it and produces an output, but it stores nothing between requests. Each API call is independent. The only "memory" a bare model has is the text you re-send inside its context window every single time. That design is elegant for a prediction engine and crippling for an agent expected to operate over hours, days, or an entire customer relationship.
The context window is often mistaken for memory, but it is closer to short-term attention than to recollection. Even as windows have grown to hundreds of thousands of tokens, three hard limits remain. First, cost and latency scale with how much you stuff into the window, so re-sending an entire history on every turn is wasteful and slow. Second, models attend unevenly across long inputs, and important details buried in the middle can be effectively ignored — the well-documented "lost in the middle" effect. Third, the window is finite and ephemeral; once a session ends, whatever was in it is gone unless something deliberately wrote it down.
External memory solves this by storing information outside the model and selectively feeding the right pieces back in when they are relevant. Instead of carrying the full transcript forever, the system distills, indexes, and retrieves. This is closely related to the broader discipline of context engineering, which treats the contents of the context window as a resource to be managed rather than assumed. Memory is the persistence side of that discipline: deciding what is worth keeping, how to store it, and how to bring it back at the right moment.
The payoff is concrete. An agent with memory can greet a returning customer with full awareness of their last three tickets, resume a half-finished onboarding workflow after an interruption, apply a correction a user made last week without being told again, and avoid repeating a question it already asked. Without memory, every interaction starts from zero, and the "intelligent" system feels amnesiac.
Agent memory divides into two broad layers that mirror how human cognition is often described: short-term (working) memory for the task at hand, and long-term memory for everything worth keeping beyond it. Getting this split right is the foundation of every memory architecture.
Short-term memory is the information the agent is actively using to complete the current task. In practice it lives in two places: the context window (the running conversation, recent tool outputs, and the active instructions) and a scratchpad — a temporary workspace where the agent records intermediate reasoning, plans, and partial results while it works through a multi-step problem.
Working memory is volatile by design. It is large enough to hold the immediate task and is cleared or compacted when the task completes. The engineering challenge is keeping it focused. As a task grows, the scratchpad and history can balloon past the window, so systems apply compaction: summarizing earlier steps, dropping resolved sub-tasks, and keeping only what the next step needs. Done well, working memory gives the agent enough situational awareness to act coherently without drowning in its own history.
Long-term memory is everything the agent should remember after the current task ends. It persists in external storage and is retrieved selectively. Long-term memory is not one thing; it splits into three functionally distinct types — episodic, semantic, and procedural — each answering a different question about what the agent knows.
Long-term agent memory is best understood as three categories: episodic memory (what happened), semantic memory (what is true), and procedural memory (how to do things). Designing each one explicitly prevents the common failure of dumping everything into a single undifferentiated store and hoping retrieval sorts it out.
Episodic memory records specific events and experiences — the dated, contextual history of what the agent and user did together. A support agent's episodic memory might hold "On 3 May the customer reported a failed export and we resolved it by resetting their API token." It is time-stamped, narrative, and tied to particular interactions. Episodic memory is what lets an agent say "last time we tried X, it didn't work, so let's try Y," and it is the basis for personalization and continuity across sessions.
Semantic memory holds stable facts and structured knowledge stripped of the episode that produced them. From the support example, the semantic fact extracted might be "this customer's account uses SSO and cannot use password reset." Semantic memory is the agent's evolving model of entities it cares about — users, accounts, products, preferences, relationships — expressed as durable facts rather than dated stories. It is the layer most likely to overlap with an enterprise knowledge base, a distinction we unpack in the memory-versus-RAG section.
Procedural memory captures how to perform tasks — the workflows, rules, and refined instructions the agent has accumulated. This includes system prompts, tool-use patterns, and learned corrections such as "always confirm the shipping address before issuing a refund." Procedural memory is what allows an agent to improve at a recurring job rather than relitigating the approach each time. In sophisticated systems, it can be updated as the agent discovers better strategies, which is one of the clearer routes toward agents that genuinely get better with use.
| Memory type | Holds what | Implemented by | Example |
|---|---|---|---|
| Short-term / working | The current task: live conversation, recent tool outputs, intermediate reasoning | Context window plus a scratchpad; managed with summarization and compaction | The running multi-step plan the agent is executing right now |
| Episodic (long-term) | Specific past events and interactions, time-stamped and narrative | Vector store of interaction summaries; event logs keyed by user or session | "On 3 May we fixed this customer's failed export by resetting their token" |
| Semantic (long-term) | Durable facts and structured knowledge about entities | Vector store of fact snippets and/or a knowledge graph of entities and relationships | "This account uses SSO and cannot reset passwords" |
| Procedural (long-term) | Learned skills, workflows, rules, and refined instructions | Versioned prompt and policy store; updated instruction sets and tool patterns | "Always confirm the shipping address before issuing a refund" |
AI memory is implemented with a combination of storage technologies and a control layer that governs what gets written, retrieved, and discarded. No single database is "the memory"; memory is an architecture. The main building blocks are vector stores with embeddings, knowledge graphs, summarization and compaction, and a memory manager that enforces explicit policies.
The workhorse of most memory systems is the vector store. When the agent decides something is worth remembering — a summary of an interaction, an extracted fact, a user preference — that text is converted into an embedding (a numerical representation of meaning) and stored. Later, when the agent faces a new situation, it embeds the current context and performs a similarity search to pull back the most semantically relevant memories. This is what makes recall associative rather than exact: the agent retrieves memories that relate to what it is doing, even if the wording differs. Vector-based memory underpins both episodic and semantic stores in many production systems.
Where relationships matter — who reports to whom, which account owns which subscription, how products depend on each other — a knowledge graph stores memory as entities and the connections between them. Graphs excel at multi-hop reasoning ("find all open issues for accounts owned by this customer's parent company") that pure similarity search handles poorly. Many mature systems combine the two: vectors for fuzzy associative recall, a graph for precise structured relationships. Semantic memory in particular benefits from graph representation.
Raw transcripts are too bulky and too noisy to store wholesale. Summarization compresses interactions into the durable essence worth keeping, and compaction keeps working memory within budget by folding older turns into concise summaries. This is also where extraction happens: a memory pipeline reads a finished interaction, decides what is genuinely worth remembering, and writes distilled episodic, semantic, or procedural entries rather than dumping the whole exchange. Good compaction is the difference between a memory store that stays sharp and one that fills with redundant clutter.
The component that ties it all together is the memory manager — the logic that decides when to write a memory, what to read back into context, and when to forget. These three policies are where most of the real engineering lives:
This control layer is increasingly standardized. Protocols such as the Model Context Protocol give agents a consistent way to connect to external memory and data services, and memory is becoming a first-class component of emerging AI operating systems that coordinate models, tools, and state across an organization.
Memory and retrieval-augmented generation are often conflated because both retrieve information and inject it into the context window — but they serve different purposes and evolve differently. RAG retrieves from an authoritative, curated knowledge base to ground answers in approved content; memory captures and evolves the agent's own accumulated experience with users and tasks. The mechanics overlap (both frequently use vector search), which is exactly why the conceptual line gets blurred.
The cleanest way to think about it: RAG answers "what does the organization know?" by reading from documentation, policies, and reference data that humans curate. Memory answers "what has this agent learned and experienced?" by reading from a store the agent itself wrote. RAG is largely read-only from the agent's perspective; memory is read-write. A knowledge base does not change because a user told the agent something; a memory store does. For a fuller treatment of the retrieval side, see our guide to enterprise RAG systems — this article deliberately links rather than re-explains it.
| Dimension | RAG | AI memory |
|---|---|---|
| Primary question | What does the organization know? | What has this agent learned and experienced? |
| Source of data | Curated knowledge base: docs, policies, reference data | The agent's own interactions, extracted facts, and learned procedures |
| Who writes it | Humans / content pipelines (largely read-only to the agent) | The agent and memory manager (read-write) |
| Lifecycle | Updated when source content changes | Continuously written, updated, superseded, and forgotten |
| Personalization | Generally the same for all users | Specific to a user, account, or session |
| Typical use | Grounding answers in authoritative facts to reduce hallucination | Continuity, personalization, and learning across interactions |
In production, the two are complementary, not competitive. A well-designed enterprise agent uses RAG to ground its answers in trustworthy source material and uses memory to remember who it is talking to, what was decided last time, and how this particular workflow is meant to run. Treating them as the same thing leads to architectures that either personalize on top of stale facts or answer authoritatively while forgetting the conversation.
Because agent memory stores information about real people and real business operations, it is subject to the same data-governance obligations as any other system of record — and it introduces new risks because it is generated and updated automatically. Governance cannot be an afterthought; it must be designed into the write, read, and forget policies from the start.
Memory stores frequently capture personal data: names, contact details, account history, sometimes sensitive information disclosed in conversation. The write policy must classify and, where appropriate, redact or tokenize PII before it is persisted, and the system should know which memories contain personal data so they can be handled accordingly. Storing everything verbatim "just in case" is the fastest route to a privacy incident.
Regulations such as the GDPR grant individuals the right to have their data deleted, which means a memory system must support targeted erasure — finding and removing every memory tied to a person on request. That is far harder if memories were stored as opaque blobs with no provenance. Designing memory with clear ownership (which user or account a memory belongs to) and retention limits (how long a memory type lives before it expires) makes deletion and compliance tractable rather than a forensic exercise.
Not every agent or user should see every memory. Memories must inherit access controls so that an agent acting for one customer cannot retrieve another customer's history, and so internal-only facts are not surfaced in the wrong context. This matters acutely in multi-agent systems, where several agents may share or hand off memory; without scoping, shared memory becomes a data-leak vector. Memory access control should align with the organization's existing identity and permission model rather than inventing a parallel one.
When an agent makes a decision based on a remembered fact, you need to be able to answer "why did it do that, and where did that memory come from?" Auditable memory keeps provenance: what was written, when, from which interaction, and what was retrieved into context for a given decision. This is essential for debugging, for trust, and for satisfying auditors that the system's behavior can be explained and reconstructed. Memory without an audit trail is a black box that becomes impossible to defend.
Organizations adopt memory in stages, and naming the stages helps teams set realistic targets. The progression runs from no memory at all to fully governed, self-managing memory.
Most enterprises today sit between Level 1 and Level 2. The strategic goal is not to leap to Level 4 everywhere, but to reach the level each use case actually requires — with governance arriving no later than durable long-term memory, never bolted on after a store of personal data already exists.
The practical question is how to add memory without creating a sprawling, ungovernable data store. A disciplined approach starts narrow and treats memory as a deliberate subsystem, not a feature toggle.
This is the stage where many teams weigh building a memory layer in-house against bringing in specialist help. The model layer is increasingly commoditized; the durable advantage sits in the surrounding architecture — memory, retrieval, governance, and orchestration — that is genuinely hard to get right. As an AI engineering partner, Mind Supernova builds these memory and context layers for global enterprise clients, drawing on our team's collective experience designing agent architectures where memory is governed and auditable rather than improvised. The aim of sharing this framework is to help you design memory deliberately, whether you build it yourself or with a partner.
An AI memory system is the external layer that lets a large language model store, retrieve, and reuse information across turns, sessions, and tasks. Because LLMs are stateless and forget everything outside their current context window, a memory system uses storage such as vector databases and knowledge graphs, plus a memory manager that decides what to write, read, and forget, to give the AI durable recollection and the ability to behave consistently over time.
Short-term (working) memory holds the information an agent needs for the task it is doing right now — the live conversation, recent tool outputs, and a scratchpad of intermediate reasoning — and it is cleared or compacted when the task ends. Long-term memory persists beyond the current task in external storage and splits into episodic memory (past events and interactions), semantic memory (durable facts), and procedural memory (learned skills and instructions), retrieved selectively when relevant.
No, though they overlap and often use the same vector-search technology. Retrieval-augmented generation pulls information from a curated, authoritative knowledge base to ground answers, and it is largely read-only to the agent. Memory captures and evolves the agent's own experience — what a user said, what was decided, how a workflow runs — and is read-write. RAG answers "what does the organization know?" while memory answers "what has this agent learned?" Most production systems use both together.
After an interaction, a memory pipeline summarizes and extracts what is worth keeping, converts it into embeddings, and stores it in a vector database (and sometimes a knowledge graph for relationships). When the user returns, the agent embeds the new context, performs a similarity search to retrieve the most relevant past memories, and injects them back into its context window. This selective recall — rather than re-sending entire transcripts — is how agents maintain continuity efficiently.
By designing governance into the memory policies. Classify and redact or tokenize PII before it is written, tag each memory with the user or account it belongs to, apply retention limits so memories expire, and support targeted deletion to satisfy rights such as the GDPR's right to be forgotten. Enforce access control so agents only retrieve memories they are authorized to see, and keep an audit trail of what was written and retrieved so decisions can be explained and defended.
Because LLMs are stateless — they retain nothing between requests, and the context window is finite, costly to fill, and erased when a session ends. Without external memory, every interaction starts from zero and the system cannot personalize, resume long-running tasks, or learn from prior corrections. An external memory layer stores information outside the model and feeds the relevant pieces back in on demand, which is what turns a clever text predictor into an agent that genuinely remembers.
Memory is the layer that turns a capable but forgetful model into a dependable enterprise agent. The model reasons; memory gives it continuity, personalization, and the ability to improve. Designing it well means distinguishing short-term working memory from long-term episodic, semantic, and procedural memory, implementing each with the right mix of vector stores, knowledge graphs, and summarization, and wrapping the whole thing in explicit write, read, and forget policies that are private, scoped, and auditable from the start.
The organizations getting the most from agentic AI are the ones treating memory as core architecture rather than an afterthought — and pairing it with retrieval so the agent is both grounded and continuous. If you are mapping out how memory, RAG, and governance should fit together for your own agents, that design conversation is exactly where the missing layer stops being missing.
Data annotation for generative AI: labeling types, RLHF and preference data, quality control, and why teams ou...

How to build high-quality AI training data at scale: sourcing, pipelines, synthetic data, quality control, and...

Fine-tuning vs RAG vs prompting, methods like LoRA and RLHF, when to fine-tune an LLM, costs, and how to outso...