
The Enterprise AI Stack of 2026: Technologies, Architectures, and Best Practices
A practical, layer-by-layer reference architecture for the modern enterprise AI stack in 2026, with technology...
What multi-agent systems are, how they differ from single agents, the four coordination topologies, the real tradeoffs, and when one agent is the better choice.
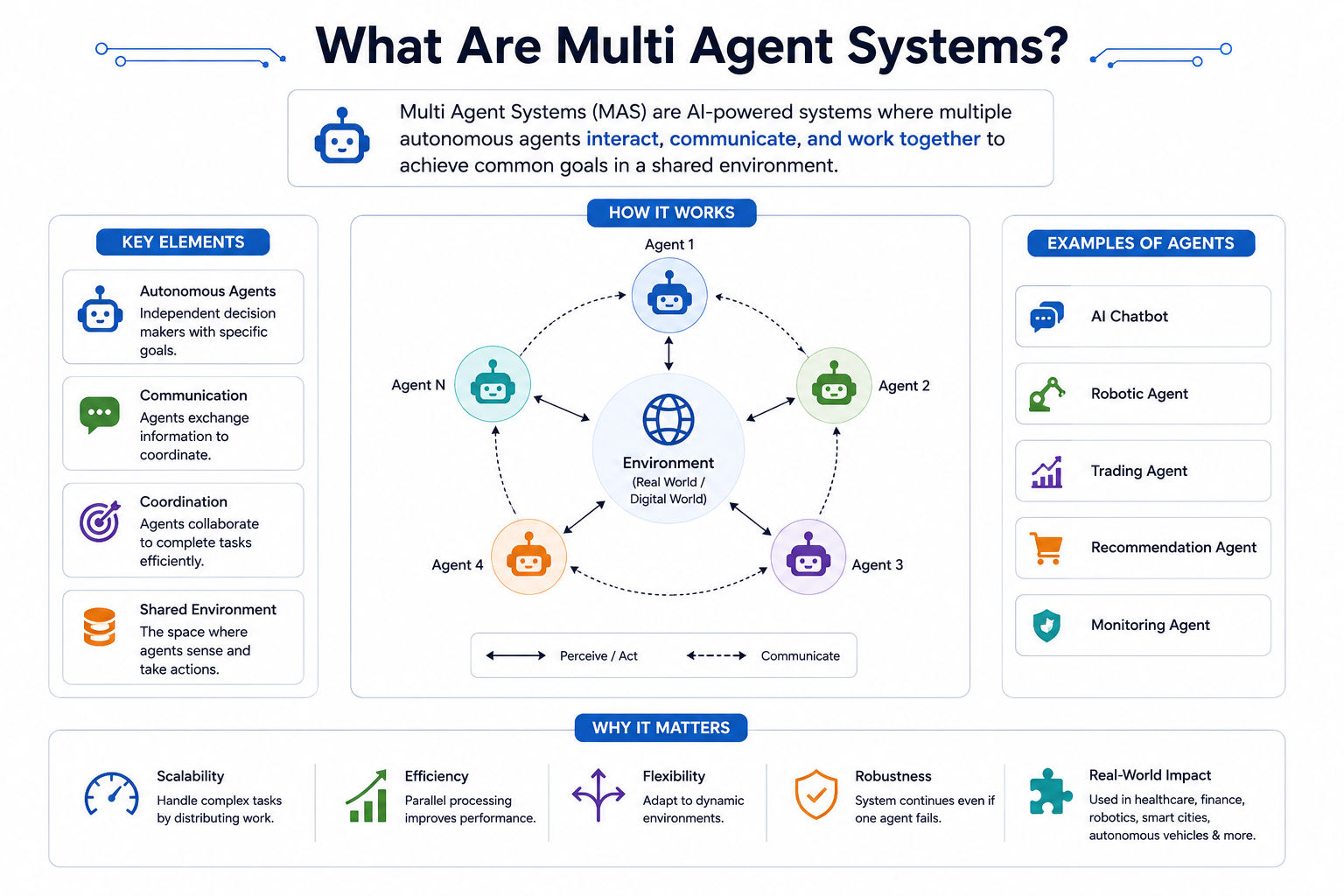
A multi-agent system is an architecture in which several semi-autonomous AI agents, each with its own role, tools, and context, coordinate to accomplish a task that would be impractical for a single agent to handle alone. Instead of one model trying to plan, research, write, and verify in a single sprawling context window, the work is decomposed across specialized agents that communicate, hand off intermediate results, and converge on an outcome. For business and technical leaders, the shift from single-agent to multi-agent design is less about novelty and more about managing complexity, reliability, and cost at enterprise scale.
The term gets used loosely. Some vendors call any workflow with two prompts a "multi-agent system," while others reserve it for fully autonomous swarms negotiating with one another. The practical definition that matters for engineering decisions sits in between: a multi-agent system exists when you have two or more agents that each maintain their own reasoning loop, can take actions independently, and exchange information to reach a shared goal. The moment you introduce a second independent reasoning loop, you inherit a coordination problem, and coordination is where most of the engineering effort, and most of the failure modes, actually live.
This guide explains what changes when you move from a single agent to a multi-agent architecture, walks through the four coordination topologies you will encounter in production, examines how agents communicate and share context, and gives you an honest accounting of the tradeoffs. It also covers the implementation discipline, decomposition, role design, shared memory, evaluation, and guardrails, that separates a multi-agent system that ships from one that quietly burns budget. Crucially, it makes the case that multi-agent is not automatically better. For a large share of enterprise tasks, a single well-instrumented agent remains the correct choice.
Key Takeaways
A multi-agent system (MAS) is a software architecture where multiple AI agents work together, each handling a distinct part of a larger objective, and coordinate through structured communication. Each agent typically wraps a language model with a defined role, a set of tools it is allowed to call, a scoped context window, and a stopping condition. One agent might be responsible only for retrieving and summarizing source documents; another only for drafting; another only for fact-checking the draft against the sources. The system's intelligence emerges from the division of labor and the protocol that connects the parts.
To understand why this matters, it helps to recall what a single agent already does. A single agent runs a loop: it receives a goal, reasons about the next step, calls a tool, observes the result, and repeats until it decides the task is done. That loop is the foundation of all agentic workflows, and for many tasks it is entirely sufficient. A multi-agent system simply runs several of these loops in parallel or in sequence and adds a layer that decides who does what and how results are combined. If you are still mapping the difference between a chatbot, a workflow, and a true agent, the enterprise agent development playbook covers that foundation in depth.
The reason engineers reach for multiple agents is rarely "it sounds advanced." It is almost always one of three concrete pressures. First, context overload: a single agent handling research, synthesis, and verification accumulates so much in its context window that reasoning quality degrades and costs climb. Second, conflicting skill profiles: a creative drafting agent and a skeptical verification agent benefit from different system prompts, different temperatures, and different tools, and forcing them into one persona produces mediocre results on both. Third, genuine parallelism: when ten subtasks are independent, running them concurrently across ten agents is dramatically faster than one agent grinding through them in series.
The single most important decision in agent architecture is whether you need more than one agent at all. Moving from a single agent to a multi-agent design changes four things: where context lives, how errors propagate, how you debug failures, and how much you spend. Each of these shifts in a direction that adds capability but also adds risk, which is why the choice should be deliberate rather than aspirational.
With a single agent, all reasoning happens in one continuous context. That makes the system easy to trace, because there is one log of one loop, and easy to reason about, because there is one decision-maker. The downside is that the agent must hold every concern at once, and long-running tasks eventually saturate the context window or drift off-objective. With a multi-agent system, each agent holds only what it needs, which keeps individual reasoning sharp, but the overall state is now distributed across agents and message passing, which makes the system harder to observe end to end.
Error propagation also changes character. In a single agent, a mistake is usually visible in the next step and can self-correct within the loop. In a multi-agent system, one agent's bad output becomes another agent's trusted input. If your research agent hallucinates a statistic and your writing agent treats it as ground truth, the error is now laundered through a handoff and is far harder to catch. This is why verification agents and explicit cross-checking become essential as agent count grows.
| Dimension | Single Agent | Multi-Agent System |
|---|---|---|
| Best for | Tightly scoped, sequential, latency-sensitive tasks | Broad, decomposable, or multi-skill tasks |
| Context handling | One window; can saturate on long tasks | Scoped per agent; sharper but distributed |
| Latency | Lower; one loop, fewer round trips | Higher per call, but parallelism can cut wall-clock time |
| Cost | Predictable, lower token volume | Higher; coordination and overlap multiply tokens |
| Reliability | Single point of failure, but self-correcting in-loop | Errors compound across handoffs; needs verification |
| Debuggability | One trace, easy to follow | Distributed traces, harder root-cause analysis |
| Pros | Simple, cheap, transparent, fast to ship | Specialization, parallelism, handles scale and breadth |
| Cons | Hits a ceiling on complex, broad work | Operationally heavy, costly, harder to evaluate |
A useful rule of thumb: start with a single agent and only split when you can name the specific bottleneck that multiple agents solve. If you cannot articulate whether you are buying parallelism, specialization, or context relief, you are probably adding agents for their own sake, and you will pay the coordination tax without the benefit.
The coordination topology is the pattern that determines how agents are connected and how control flows between them. There are four that cover the overwhelming majority of production systems: orchestrator-worker, hierarchical, network/peer, and blackboard/shared-state. They differ in who decides what happens next and how tightly the agents are coupled. Choosing the right one is the highest-leverage architectural decision you will make, because it shapes latency, cost, reliability, and how hard the system is to debug.
| Topology | Control flow | Strengths | Watch out for |
|---|---|---|---|
| Orchestrator-worker | Central agent delegates to workers | Simple to reason about, easy to add workers | Orchestrator becomes a bottleneck and single point of failure |
| Hierarchical | Layers of supervisors over sub-teams | Scales to large, multi-stage problems | Latency stacks up; deep trees are hard to trace |
| Network / peer | Agents message each other directly | Flexible, resilient, no central choke point | Unpredictable, can loop or fail to converge |
| Blackboard / shared-state | Agents read/write a shared workspace | Decoupled, good for opportunistic collaboration | Contention, stale reads, needs strong state discipline |
The orchestrator-worker pattern uses one central agent that decomposes the goal, delegates subtasks to specialized worker agents, and synthesizes their results into a final answer. It is the most common starting point for enterprise multi-agent systems because it maps cleanly onto how teams already think: a manager assigns work, specialists execute, and the manager assembles the deliverable. The orchestrator holds the high-level plan and the global context, while each worker holds only the narrow context for its assigned subtask.
This topology shines when a task naturally breaks into independent pieces. A competitive-research request, for example, can have the orchestrator spawn one worker per competitor, each retrieving and summarizing in parallel, then have the orchestrator merge the summaries into a comparison. The pattern is also easy to extend: adding a new capability often means adding a new worker and teaching the orchestrator when to call it. The cost is that the orchestrator is both a bottleneck and a single point of failure. If its planning is wrong, every worker does the wrong thing efficiently, and the synthesis step can itself become a context-overload problem when many worker outputs must be combined.
A hierarchical topology stacks orchestrators: a top-level supervisor coordinates mid-level supervisors, each of which manages its own team of workers. It is the natural answer when a single orchestrator would have too many direct reports or when the problem has clearly distinct phases that each warrant their own sub-team. Think of an end-to-end software delivery system where a top supervisor coordinates a "requirements" sub-team, a "implementation" sub-team, and a "QA" sub-team, each with its own internal orchestrator-worker structure.
Hierarchy buys you scale and modularity. Each layer abstracts the one below it, so the top supervisor reasons about phases rather than individual tool calls, which keeps its context manageable. The price is latency and traceability. Every additional layer adds round trips, and a request that passes through three levels of supervision before reaching a worker accumulates real wall-clock time. When something goes wrong, root-causing a failure several layers deep is genuinely hard, which is why hierarchical systems demand strong observability and per-layer evaluation before they are trusted with production traffic.
In a network or peer topology, agents communicate directly with one another without a central coordinator, each deciding whom to talk to based on the task at hand. There is no boss; coordination emerges from the conversation. This is the pattern most often associated with "agent swarms" and with research demonstrations where agents negotiate, debate, or critique one another to refine an answer. A peer design can be remarkably resilient, because there is no single choke point, and remarkably flexible, because the communication graph forms dynamically.
The tradeoff is predictability. Without a central authority deciding when the work is done, peer systems can loop indefinitely, fail to converge, or burn tokens in circular debates. They are harder to evaluate because the execution path differs from run to run, and harder to bound in cost. In enterprise settings, pure peer topologies are still relatively rare for production workloads; they tend to appear in controlled subroutines, such as a small debate-and-vote ensemble for a high-stakes decision, rather than as the backbone of a whole system. When you do use them, hard caps on message count and explicit termination conditions are non-negotiable.
The blackboard pattern, borrowed from classical AI, has agents collaborate indirectly by reading from and writing to a shared workspace rather than messaging each other directly. Each agent watches the blackboard, contributes when it can make progress, and the solution accumulates incrementally as a shared artifact. This decouples agents in time and identity: an agent does not need to know which other agent will use its output, only that it has advanced the shared state. It suits opportunistic, loosely ordered work where you cannot predict in advance which agent should act next.
The shared workspace is also where this topology overlaps with the broader question of AI memory systems, since the blackboard is effectively a working memory that multiple agents must read and write consistently. The risks are the classic ones of shared state: contention when agents write simultaneously, stale reads when an agent acts on outdated information, and the need for clear conventions about what each region of the blackboard means. Without disciplined state management, a blackboard system degrades into agents stepping on one another's work. With it, it offers a clean way to let specialized agents contribute to a single evolving result.
Agents in a multi-agent system communicate by passing structured messages and by sharing context through memory, and the discipline of how they do this determines whether the system is reliable or chaotic. Communication is not just "agent A talks to agent B." It is a set of decisions about message format, what context is shared versus scoped, how state is persisted, and increasingly, what protocol standardizes tool and data access across agents.
At the message level, robust systems favor structured, typed handoffs over free-form natural language. When the orchestrator delegates to a worker, it should pass a clearly bounded instruction, the specific context the worker needs, and the expected output shape, rather than dumping its entire conversation history. Tight, explicit message contracts are what keep context windows small and reasoning sharp. They also make the system testable, because you can evaluate each agent against a defined input and output contract rather than against the emergent behavior of the whole.
Context sharing happens along a spectrum. At one end, agents share nothing and communicate only through explicit messages, which maximizes isolation and debuggability. At the other end, all agents read from a common memory store, which maximizes coherence but risks context bloat and inconsistency. Most production systems sit in the middle: a shared long-term memory or knowledge base for durable facts, plus scoped short-term context per agent for the task at hand. Designing this split well is one of the most underrated parts of multi-agent engineering, and it connects directly to how you architect agents and MCP within enterprise software architecture.
On standardization, the emergence of open protocols is changing how agents access tools and data. The Model Context Protocol, for instance, gives agents a uniform way to connect to tools, files, and external systems, which reduces the bespoke glue code that multi-agent systems otherwise accumulate. Standard interfaces matter more as agent count grows, because every non-standard integration is a place where a handoff can break. Treating tool and data access as a stable contract, rather than reinventing it per agent, is what lets a multi-agent system scale without collapsing under its own integration weight.
The honest truth about multi-agent systems is that they trade simplicity for capability, and that trade is not always worth it. Every additional agent adds token cost, can add latency, multiplies the surface area for failure, and makes debugging harder. Leaders evaluating a multi-agent investment should weigh these four costs explicitly against the capability they expect to gain, because vendors and demos tend to showcase the upside while the operational burden shows up only in production.
Cost. Multi-agent systems consume more tokens than single agents doing comparable work, often several times more. Each agent re-establishes context, orchestrators re-read worker outputs, and verification agents reprocess content that has already been generated. Industry discussion through 2025 consistently flags that naive multi-agent designs can multiply token spend without a proportional gain in quality. The discipline of keeping per-agent context tight is as much a cost-control measure as a quality one.
Latency. The latency picture is mixed. Sequential multi-agent chains are slower than a single agent because each handoff is another model round trip. Parallel designs can be faster in wall-clock terms when subtasks run concurrently, but only if the work genuinely decomposes and the synthesis step does not become a new bottleneck. For latency-sensitive, user-facing applications, a single agent is frequently the better answer, and multi-agent designs are reserved for background or batch work where a few extra seconds are acceptable.
Reliability. Reliability is the subtlest tradeoff. Intuitively, more specialized agents should mean higher quality, and often they do. But reliability can also compound downward: if each agent in a five-step chain is 95 percent reliable, the end-to-end success rate is closer to 77 percent, because the failures multiply. This is why verification, retries, and explicit error handling at each handoff are not optional extras but core architecture. Without them, adding agents can lower overall reliability even as it raises peak capability.
Debuggability. Finally, multi-agent systems are harder to debug. A single agent produces one trace you can read top to bottom. A multi-agent system produces distributed traces across agents, handoffs, and shared state, and a failure may emerge from the interaction between agents rather than from any one of them. Investing in observability, structured logging of every message, every tool call, and every state change, is what makes these systems supportable. Teams that skip this find themselves unable to explain why the system did what it did, which is disqualifying for any regulated or high-stakes enterprise use.
For a large share of enterprise tasks, a single well-built agent is the better choice, and recognizing this is a sign of engineering maturity rather than a lack of ambition. The pull toward multi-agent architectures is strong because they look sophisticated, but sophistication is a cost, not a feature. The right default is the simplest architecture that meets the requirement, and you scale up only when you hit a concrete wall.
A single agent is usually the better choice when the task is tightly scoped and fits comfortably in one context window, when steps are inherently sequential so there is no parallelism to exploit, when latency matters because a human is waiting on the response, or when the task does not require genuinely distinct skill profiles. Many tasks that teams reflexively split into multiple agents, a support assistant that answers from a knowledge base, a code-review helper, a structured-data extractor, run perfectly well as one agent with good tools and a clear prompt. Adding agents to these would buy nothing but cost and complexity.
Reach for multiple agents when at least one of three conditions is clearly true. The task decomposes into independent subtasks that benefit from running in parallel. The work demands conflicting personas or skill sets that a single prompt cannot serve well, such as creative generation paired with skeptical verification. Or a single agent's context window is genuinely overwhelmed by the breadth of information the task requires. If none of these holds, a single agent is not a compromise; it is the correct design. This balanced posture, matching architecture to need rather than to trend, is the same discipline that separates durable systems from impressive demos, and it underpins how mature teams approach the broader shift from AI tools to autonomous AI workforces.
Multi-agent systems earn their complexity in enterprise scenarios that are too broad, too parallel, or too multi-skilled for a single agent. Three categories show up repeatedly in production: complex research and analysis, end-to-end operational workflows, and software delivery. In each, the work naturally decomposes and benefits from specialization, which is exactly the condition under which a multi-agent design pays off.
Deep research is a canonical multi-agent use case because the work fans out naturally. An orchestrator can decompose a research question into sub-questions, dispatch a worker per sub-question to retrieve and summarize sources in parallel, and then synthesize the findings into a coherent report with citations. Adding a dedicated verification agent that checks each claim against its source materially reduces hallucination. This pattern, parallel retrieval plus central synthesis plus independent verification, is well suited to competitive intelligence, due diligence, literature reviews, and market analysis, where breadth and source-checking both matter.
Operational workflows that span multiple systems and decision points are a strong fit for hierarchical multi-agent designs. Consider an order-to-resolution process that must interpret an incoming request, check inventory across systems, evaluate policy, take an action, and communicate the outcome. Each stage benefits from a specialized agent with the right tools and guardrails, coordinated by a supervisor that enforces the overall process. The same shape applies to procurement, claims handling, and IT operations. These systems sit at the heart of the broader move toward autonomous operations, a theme explored in how AI agents are replacing traditional software workflows.
Software delivery has become one of the most active proving grounds for multi-agent systems. A delivery pipeline can assign distinct agents to planning, implementation, testing, and review, coordinated hierarchically, with each agent specialized for its phase and equipped with the relevant tools. The verification structure is natural here: a testing agent and a review agent provide the independent checks that catch errors an implementation agent introduces. The honest caveat is that these systems are powerful but not autonomous in the hands-off sense; they amplify skilled engineers rather than replace the judgment that production software demands.
A multi-agent system succeeds or fails on engineering discipline, not on the number of agents, and five practices separate systems that ship from systems that stall: decomposition, role design, shared memory, evaluation, and guardrails. None of these is glamorous, and all of them are where the real work lives. Teams that treat multi-agent design as primarily a prompting exercise tend to produce fragile demos; teams that treat it as a distributed-systems problem produce things that survive contact with real users.
Start by decomposing the task along seams that actually exist in the problem, not along arbitrary lines. Good decomposition produces subtasks that are independent enough to parallelize or distinct enough to warrant a specialist, with clean interfaces between them. A decomposition test that works well: if you cannot describe each agent's job in one sentence and define exactly what it receives and returns, the boundary is wrong. Over-decomposition, splitting into many tiny agents, is as harmful as under-decomposition, because every boundary is a handoff that can fail and a context that must be re-established.
Each agent should have a tightly defined role: a specific responsibility, an allowed set of tools, a scoped context, and a clear stopping condition. Treat the role as a contract. The agent receives a defined input, performs one job, and returns a defined output. Resist the temptation to make any agent a generalist that "handles whatever comes up," because generalist agents are exactly the components that become unpredictable and untestable. Distinct roles also let you tune each agent independently, choosing a smaller, cheaper model for routine extraction and a more capable model for synthesis or critical reasoning.
Decide explicitly what state is shared and what is scoped. A common pattern is a durable shared memory or knowledge base for facts that multiple agents need, paired with ephemeral per-agent context for the immediate task. Shared memory must be governed: clear schemas, conventions for what each region means, and consistency rules so that one agent does not act on another's stale write. This is the layer where many multi-agent systems quietly fail, and it is closely tied to the broader discipline of enterprise memory architecture and retrieval. When agents draw on shared knowledge, grounding that knowledge in a well-built enterprise RAG system reduces the chance that one agent's hallucination contaminates the whole pipeline.
Evaluate at two levels: each agent against its own contract, and the system end to end. Per-agent evaluation lets you catch a degrading component before it poisons downstream agents, while end-to-end evaluation captures emergent failures that only appear when agents interact. Build a representative test set of real tasks, define what success looks like for each, and track quality, cost, and latency together so you can see when a quality gain is not worth its cost. Without this, you cannot tell whether adding an agent helped, and you will not catch regressions until users do.
Guardrails keep a multi-agent system from running away. Hard caps on the number of steps, message rounds, and total spend prevent runaway loops and budget surprises. Verification agents or rule-based checks at critical handoffs catch errors before they propagate. Permission scoping ensures each agent can only call the tools it genuinely needs, which limits the blast radius when an agent misbehaves. And a clear escalation path to a human for low-confidence or high-stakes decisions is what makes these systems safe to deploy in enterprise contexts. Guardrails are not a constraint on the system; they are what makes it trustworthy enough to put in front of real operations.
Most enterprises face a build-versus-partner decision on multi-agent systems, and the honest answer depends on how much of this discipline lives in-house. The orchestration logic, evaluation harnesses, memory governance, and observability described above represent real engineering effort that general application teams rarely have on hand. This is where a specialist partner adds value. As an AI engineering company, Mind Supernova helps enterprises design and build multi-agent architectures with the decomposition, evaluation, and guardrail discipline that determines whether these systems hold up in production. The goal of a good partner is not to add agents for their own sake but to deploy the simplest architecture that meets the requirement, and to make the resulting system observable, testable, and safe.
A multi-agent system is an architecture in which two or more semi-autonomous AI agents, each with its own role, tools, and context, coordinate to accomplish a task that is too complex or too broad for a single agent. Each agent runs its own reasoning loop and exchanges information with the others through structured messages or shared memory, and the system's capability emerges from the division of labor among specialized agents.
Use a single agent by default, and move to multiple agents only when you can name a specific bottleneck they solve. Multiple agents make sense when the task decomposes into independent subtasks that benefit from running in parallel, when the work requires conflicting skill profiles such as creative generation paired with skeptical verification, or when a single agent's context window is overwhelmed by the breadth of information required. If none of these conditions holds, a single agent is cheaper, faster, and easier to debug.
Four coordination topologies dominate production systems. Orchestrator-worker uses a central agent that delegates to specialized workers and is the most common starting point. Hierarchical stacks supervisors over sub-teams for large, multi-stage problems. Network or peer lets agents message each other directly without a central coordinator, offering flexibility at the cost of predictability. Blackboard or shared-state has agents collaborate indirectly through a shared workspace. Most enterprises begin with orchestrator-worker and adopt the others only when the problem demands it.
Agents communicate by passing structured, typed messages and by sharing context through memory. Robust systems favor tight, explicit message contracts, where an agent receives a bounded instruction and the specific context it needs, and returns a defined output shape, over dumping full conversation histories. Context sharing ranges from message-only isolation to a common memory store, with most production systems using a shared long-term knowledge base for durable facts plus scoped short-term context per agent. Open protocols such as the Model Context Protocol increasingly standardize how agents access tools and data.
Yes, but selectively. Orchestrator-worker and hierarchical designs run reliably in production for research, operations, and software-delivery use cases when teams invest in evaluation, observability, and guardrails. Pure peer and swarm topologies remain less common for production workloads because their execution paths are hard to bound and evaluate. Production readiness depends far more on engineering discipline, structured logging, per-agent and end-to-end evaluation, step and spend caps, and human escalation, than on the underlying models.
The main downsides are higher cost, variable latency, compounding reliability risk, and harder debugging. Multi-agent systems consume several times more tokens than comparable single agents, sequential chains add latency, and errors can compound across handoffs so that a chain of individually reliable agents has a lower end-to-end success rate. They also produce distributed traces that make root-cause analysis difficult. These costs are why multi-agent should never be a default and should be adopted only when the capability gain clearly justifies the operational burden.
Not in the hands-off sense that vendor marketing often implies. The most effective enterprise multi-agent systems amplify skilled people rather than replace them, handling decomposable and repetitive parts of complex work while routing low-confidence or high-stakes decisions to a human. In software delivery, research, and operations alike, the durable pattern is a human-in-the-loop design where agents accelerate the work and people retain judgment and accountability.
Multi-agent systems are a powerful tool for problems that are genuinely too broad, too parallel, or too multi-skilled for a single agent, but they are not a default and they are not automatically better. The capability they add, specialization and parallelism, comes with real costs in token spend, latency, reliability, and debuggability, and those costs are easy to underestimate from a demo. The mature posture is to start with the simplest architecture that meets the requirement, reach for multiple agents only when you can name the bottleneck they solve, and invest the engineering discipline, clear decomposition, defined roles, governed shared memory, rigorous evaluation, and firm guardrails, that the architecture demands.
For leaders planning their agentic roadmap, the takeaway is to resist architecture for its own sake and to match design to need. If your organization is weighing whether a single agent or a multi-agent system fits a specific workflow, and how to build it so it holds up in production, Mind Supernova works with enterprise teams to design, evaluate, and deploy agent architectures grounded in that discipline. The right number of agents is the smallest number that does the job well.
A practical, layer-by-layer reference architecture for the modern enterprise AI stack in 2026, with technology...

How to design and operate an AI workforce that lasts: the operating model, human-in-the-loop patterns, governa...

How enterprises build production AI agents: architectures, use cases, governance, and when to outsource agenti...